对于环0-n:
分别考虑0-n和1-n+0;
处理为0-2n
OI 中所说的「自动机」一般都指「确定有限状态自动机」。
自动机是 OI、计算机科学中被广泛使用的一个数学模型,其思想在许多字符串算法中都有涉及,因此推荐在学习一些字符串算法(KMP、AC 自动机、SAM)前先完成自动机的学习。学习自动机有助于理解上述算法。
字典树 是大部分 OIer 接触到的第一个自动机,接受且仅接受指定的字符串集合中的元素。
转移函数就是 Trie 上的边,接受状态是将每个字符串插入到 Trie 时到达的那个状态。
KMP 算法 可以视作自动机,基于字符串  的 KMP 自动机接受且仅接受以 为后缀的字符串,其接受状态为 。
的 KMP 自动机接受且仅接受以 为后缀的字符串,其接受状态为 。
转移函数:
AC 自动机 接受且仅接受以指定的字符串集合中的某个元素为后缀的字符串。也就是 Trie + KMP。
::: tip
这篇文章中的消息队列主要指的是分布式消息队列。
:::
“RabbitMQ?”“Kafka?”“RocketMQ?”…在日常学习与开发过程中,我们常常听到消息队列这个关键词。我也在我的多篇文章中提到了这个概念。可能你是熟练使用消息队列的老手,又或者你是不懂消息队列的新手,不论你了不了解消息队列,本文都将带你搞懂消息队列的一些基本理论。
如果你是老手,你可能从本文学到你之前不曾注意的一些关于消息队列的重要概念,如果你是新手,相信本文将是你打开消息队列大门的一板砖。
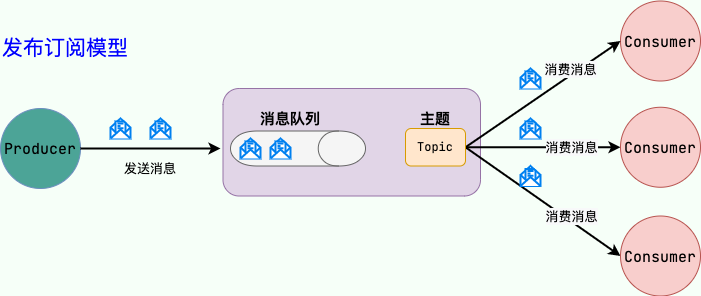
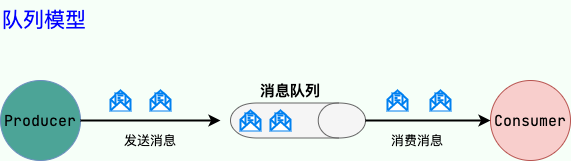
我们可以把消息队列看作是一个存放消息的容器,当我们需要使用消息的时候,直接从容器中取出消息供自己使用即可。由于队列 Queue 是一种先进先出的数据结构,所以消费消息时也是按照顺序来消费的。

参与消息传递的双方称为 生产者 和 消费者 ,生产者负责发送消息,消费者负责处理消息。
操作系统中的进程通信的一种很重要的方式就是消息队列。我们这里提到的消息队列稍微有点区别,更多指的是各个服务以及系统内部各个组件/模块之前的通信,属于一种 中间件 。
维基百科是这样介绍中间件的:
中间件(英语:Middleware),又译中间件、中介层,是一类提供系统软件和应用软件之间连接、便于软件各部件之间的沟通的软件,应用软件可以借助中间件在不同的技术架构之间共享信息与资源。中间件位于客户机服务器的操作系统之上,管理着计算资源和网络通信。
简单来说:中间件就是一类为应用软件服务的软件,应用软件是为用户服务的,用户不会接触或者使用到中间件。
除了消息队列之外,常见的中间件还有 RPC 框架、分布式组件、HTTP 服务器、任务调度框架、配置中心、数据库层的分库分表工具和数据迁移工具等等。
关于中间件比较详细的介绍可以参考阿里巴巴淘系技术的一篇回答:https://www.zhihu.com/question/19730582/answer/1663627873 。
随着分布式和微服务系统的发展,消息队列在系统设计中有了更大的发挥空间,使用消息队列可以降低系统耦合性、实现任务异步、有效地进行流量削峰,是分布式和微服务系统中重要的组件之一。
通常来说,使用消息队列主要能为我们的系统带来下面三点好处:
除了这三点之外,消息队列还有其他的一些应用场景,例如实现分布式事务、顺序保证和数据流处理。
如果在面试的时候你被面试官问到这个问题的话,一般情况是你在你的简历上涉及到消息队列这方面的内容,这个时候推荐你结合你自己的项目来回答。
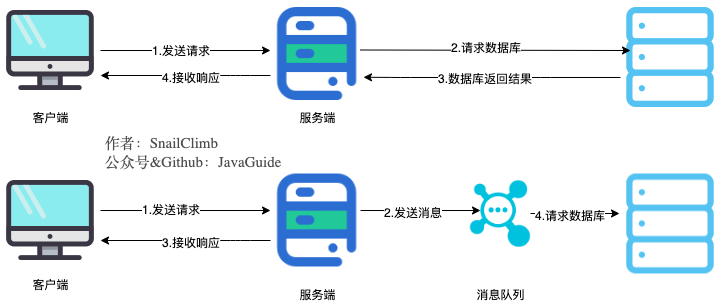
将用户请求中包含的耗时操作,通过消息队列实现异步处理,将对应的消息发送到消息队列之后就立即返回结果,减少响应时间,提高用户体验。随后,系统再对消息进行消费。
因为用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败。因此,使用消息队列进行异步处理之后,需要适当修改业务流程进行配合,比如用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
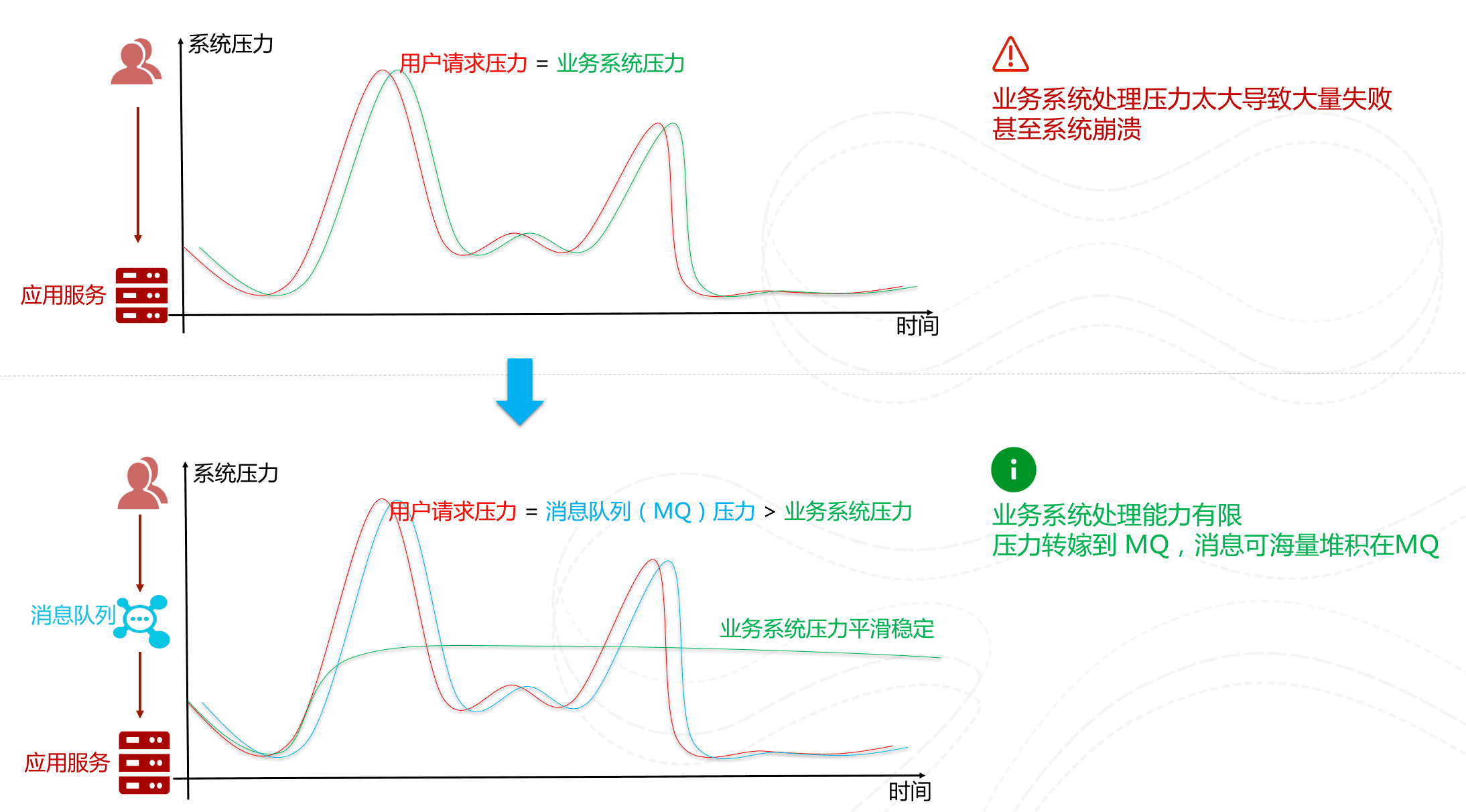
先将短时间高并发产生的事务消息存储在消息队列中,然后后端服务再慢慢根据自己的能力去消费这些消息,这样就避免直接把后端服务打垮掉。
举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
使用消息队列还可以降低系统耦合性。如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。
生产者(客户端)发送消息到消息队列中去,消费者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合,这显然也提高了系统的扩展性。
消息队列使用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。 从上图可以看到消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计。
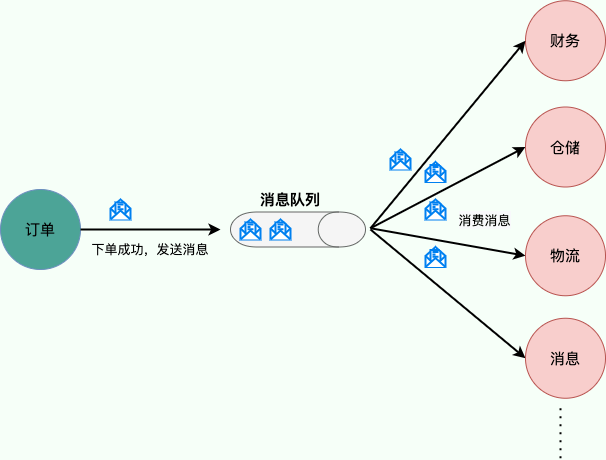
例如,我们商城系统分为用户、订单、财务、仓储、消息通知、物流、风控等多个服务。用户在完成下单后,需要调用财务(扣款)、仓储(库存管理)、物流(发货)、消息通知(通知用户发货)、风控(风险评估)等服务。使用消息队列后,下单操作和后续的扣款、发货、通知等操作就解耦了,下单完成发送一个消息到消息队列,需要用到的地方去订阅这个消息进行消息即可。
另外,为了避免消息队列服务器宕机造成消息丢失,会将成功发送到消息队列的消息存储在消息生产者服务器上,等消息真正被消费者服务器处理后才删除消息。在消息队列服务器宕机后,生产者服务器会选择分布式消息队列服务器集群中的其他服务器发布消息。
备注: 不要认为消息队列只能利用发布-订阅模式工作,只不过在解耦这个特定业务环境下是使用发布-订阅模式的。除了发布-订阅模式,还有点对点订阅模式(一个消息只有一个消费者),我们比较常用的是发布-订阅模式。另外,这两种消息模型是 JMS 提供的,AMQP 协议还提供了另外 5 种消息模型。
分布式事务的解决方案之一就是 MQ 事务。
RocketMQ、 Kafka、Pulsar、QMQ 都提供了事务相关的功能。事务允许事件流应用将消费,处理,生产消息整个过程定义为一个原子操作。
详细介绍可以查看 分布式事务详解(付费) 这篇文章。

在很多应用场景中,处理数据的顺序至关重要。消息队列保证数据按照特定的顺序被处理,适用于那些对数据顺序有严格要求的场景。大部分消息队列,例如 RocketMQ、RabbitMQ、Pulsar、Kafka,都支持顺序消息。
消息发送后不会立即被消费,而是指定一个时间,到时间后再消费。大部分消息队列,例如 RocketMQ、RabbitMQ、Pulsar、Kafka,都支持定时/延时消息。
MQTT(消息队列遥测传输协议)是一种轻量级的通讯协议,采用发布/订阅模式,非常适合于物联网(IoT)等需要在低带宽、高延迟或不可靠网络环境下工作的应用。它支持即时消息传递,即使在网络条件较差的情况下也能保持通信的稳定性。
RabbitMQ 内置了 MQTT 插件用于实现 MQTT 功能(默认不启用,需要手动开启)。
针对分布式系统产生的海量数据流,如业务日志、监控数据、用户行为等,消息队列可以实时或批量收集这些数据,并将其导入到大数据处理引擎中,实现高效的数据流管理和处理。
JMS(JAVA Message Service,java 消息服务)是 Java 的消息服务,JMS 的客户端之间可以通过 JMS 服务进行异步的消息传输。JMS(JAVA Message Service,Java 消息服务)API 是一个消息服务的标准或者说是规范,允许应用程序组件基于 JavaEE 平台创建、发送、接收和读取消息。它使分布式通信耦合度更低,消息服务更加可靠以及异步性。
JMS 定义了五种不同的消息正文格式以及调用的消息类型,允许你发送并接收以一些不同形式的数据:
StreamMessage:Java 原始值的数据流MapMessage:一套名称-值对TextMessage:一个字符串对象ObjectMessage:一个序列化的 Java 对象BytesMessage:一个字节的数据流ActiveMQ(已被淘汰) 就是基于 JMS 规范实现的。
使用队列(Queue)作为消息通信载体;满足生产者与消费者模式,一条消息只能被一个消费者使用,未被消费的消息在队列中保留直到被消费或超时。比如:我们生产者发送 100 条消息的话,两个消费者来消费一般情况下两个消费者会按照消息发送的顺序各自消费一半(也就是你一个我一个的消费。)
发布订阅模型(Pub/Sub) 使用主题(Topic)作为消息通信载体,类似于广播模式;发布者发布一条消息,该消息通过主题传递给所有的订阅者。
AMQP,即 Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准 高级消息队列协议(二进制应用层协议),是应用层协议的一个开放标准,为面向消息的中间件设计,兼容 JMS。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件同产品,不同的开发语言等条件的限制。
RabbitMQ 就是基于 AMQP 协议实现的。
| 对比方向 | JMS | AMQP |
|---|---|---|
| 定义 | Java API | 协议 |
| 跨语言 | 否 | 是 |
| 跨平台 | 否 | 是 |
| 支持消息类型 | 提供两种消息模型:①Peer-2-Peer;②Pub/sub | 提供了五种消息模型:①direct exchange;②fanout exchange;③topic change;④headers exchange;⑤system exchange。本质来讲,后四种和 JMS 的 pub/sub 模型没有太大差别,仅是在路由机制上做了更详细的划分; |
| 支持消息类型 | 支持多种消息类型 ,我们在上面提到过 | byte[](二进制) |
总结:
TextMessage、MapMessage 等复杂的消息类型;而 AMQP 仅支持 byte[] 消息类型(复杂的类型可序列化后发送)。RPC 和消息队列都是分布式微服务系统中重要的组件之一,下面我们来简单对比一下两者:
RPC 和消息队列本质上是网络通讯的两种不同的实现机制,两者的用途不同,万不可将两者混为一谈。
![]()
Kafka 是 LinkedIn 开源的一个分布式流式处理平台,已经成为 Apache 顶级项目,早期被用来用于处理海量的日志,后面才慢慢发展成了一款功能全面的高性能消息队列。
流式处理平台具有三个关键功能:
Kafka 是一个分布式系统,由通过高性能 TCP 网络协议进行通信的服务器和客户端组成,可以部署在在本地和云环境中的裸机硬件、虚拟机和容器上。
在 Kafka 2.8 之前,Kafka 最被大家诟病的就是其重度依赖于 Zookeeper 做元数据管理和集群的高可用。在 Kafka 2.8 之后,引入了基于 Raft 协议的 KRaft 模式,不再依赖 Zookeeper,大大简化了 Kafka 的架构,让你可以以一种轻量级的方式来使用 Kafka。
不过,要提示一下:如果要使用 KRaft 模式的话,建议选择较高版本的 Kafka,因为这个功能还在持续完善优化中。Kafka 3.3.1 版本是第一个将 KRaft(Kafka Raft)共识协议标记为生产就绪的版本。

Kafka 官网:http://kafka.apache.org/
Kafka 更新记录(可以直观看到项目是否还在维护):https://kafka.apache.org/downloads
![]()
RocketMQ 是阿里开源的一款云原生“消息、事件、流”实时数据处理平台,借鉴了 Kafka,已经成为 Apache 顶级项目。
RocketMQ 的核心特性(摘自 RocketMQ 官网):
根据官网介绍:
Apache RocketMQ 自诞生以来,因其架构简单、业务功能丰富、具备极强可扩展性等特点被众多企业开发者以及云厂商广泛采用。历经十余年的大规模场景打磨,RocketMQ 已经成为业内共识的金融级可靠业务消息首选方案,被广泛应用于互联网、大数据、移动互联网、物联网等领域的业务场景。
RocketMQ 官网:https://rocketmq.apache.org/ (文档很详细,推荐阅读)
RocketMQ 更新记录(可以直观看到项目是否还在维护):https://github.com/apache/rocketmq/releases
![]()
RabbitMQ 是采用 Erlang 语言实现 AMQP(Advanced Message Queuing Protocol,高级消息队列协议)的消息中间件,它最初起源于金融系统,用于在分布式系统中存储转发消息。
RabbitMQ 发展到今天,被越来越多的人认可,这和它在易用性、扩展性、可靠性和高可用性等方面的卓著表现是分不开的。RabbitMQ 的具体特点可以概括为以下几点:
RabbitMQ 官网:https://www.rabbitmq.com/ 。
RabbitMQ 更新记录(可以直观看到项目是否还在维护):https://www.rabbitmq.com/news.html
![]()
Pulsar 是下一代云原生分布式消息流平台,最初由 Yahoo 开发 ,已经成为 Apache 顶级项目。
Pulsar 集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性,被看作是云原生时代实时消息流传输、存储和计算最佳解决方案。
Pulsar 的关键特性如下(摘自官网):
Pulsar 官网:https://pulsar.apache.org/
Pulsar 更新记录(可以直观看到项目是否还在维护):https://github.com/apache/pulsar/releases
目前已经被淘汰,不推荐使用,不建议学习。
参考《Java 工程师面试突击第 1 季-中华石杉老师》
| 对比方向 | 概要 |
|---|---|
| 吞吐量 | 万级的 ActiveMQ 和 RabbitMQ 的吞吐量(ActiveMQ 的性能最差)要比十万级甚至是百万级的 RocketMQ 和 Kafka 低一个数量级。 |
| 可用性 | 都可以实现高可用。ActiveMQ 和 RabbitMQ 都是基于主从架构实现高可用性。RocketMQ 基于分布式架构。 Kafka 也是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 时效性 | RabbitMQ 基于 Erlang 开发,所以并发能力很强,性能极其好,延时很低,达到微秒级,其他几个都是 ms 级。 |
| 功能支持 | Pulsar 的功能更全面,支持多租户、多种消费模式和持久性模式等功能,是下一代云原生分布式消息流平台。 |
| 消息丢失 | ActiveMQ 和 RabbitMQ 丢失的可能性非常低, Kafka、RocketMQ 和 Pulsar 理论上可以做到 0 丢失。 |
总结:
x86架构计算机是==按字节寻址==的。也就是一个内存单元是字节。
大家接触计算机就会听到各种位宽,多少位的CPU,多少位的操作系统,多少位的数据总线、地址总线等,很多时候大家纠结这些位宽之间有什么关系?有些资料或者学习视频里对这些概念的解释也是不准确,甚至是错误的,例如下面的说法:
1 数据总线和CPU的字长总是一致;
2 数据总线和地址总线位数一致;
都是常见的错误表述!
要搞清楚各种位宽的含义,先要解释下各位宽的物理意义:
一、 计算机的“字长”—俗称是多少位的CPU
这里上下文特指计算机的字长,它就是CPU里寄存器的宽度,学了计算机组成应该知道,CPU里除了控制器、运算器之外,还有很多寄存器(当然现在CPU还有Cache等),机器的字长就是其中通用寄存器(GPR)的位宽。
CPU在设计的时候会让运算器和通用寄存器的位宽保持一致,在硬件上就是CPU一次能进行的多少位数据运算,所以字长反应了CPU的数据运算能力(一次可以进行几位的数据运算,得到的结果是几位的)。
这里还要提一下编程人员经常说的字长,我们姑且叫它是软件字长吧,这个和上面的机器字长不一样,机器字长就叫硬件字长吧。可以看下面这篇文章,这里不赘述了。
https://www.bilibili.com/read/cv19069811
二、 数据总线位宽
有些资料里说数据总线宽度和机器字长一致,这种说法是不准确的,数据总线细分又分外部数据总线和内部数据总线,处理器在设计时一般通用寄存器GPR和运算器及内部数据总线是一致的,外部数据总线会链接内存、显卡、IO、设备等,外部数据总线反应的是CPU和外设的数据传送能力,而平时说的数据总线没特殊说明一般指外部数据总线,那“数据总线宽度和机器字长一致”这种说的就是不准确的。
三、 地址总线位宽
在计算机里内存寻址分逻辑地址寻址和物理地址寻址,地址线反应的就是物理地址的寻址能力。
那什么是逻辑寻址呢?学过计算机组成应该知道,指令执行时涉及指令寻址(下一条指令在哪里)和操作数寻址(指令执行时操作数在哪里),指令寻址肯定都是内存寻址(代码加载到内存中后才被执行),而操作数寻址中除了立即数寻址和寄存器寻址,其他都要进行内存访问,那就需要计算内存地址,内存地址的计算除了寄存器间接寻址不需要计算内存地址外,其他大都需要运算器去计算访存位置,上面介绍计算机“字长”概念时提到了,运算器字长决定了运算结果的位数,所以字长决定了计算机的逻辑地址寻址能力,在平时我们提的程序的地址空间其实说的都是这个逻辑地址范围。
很多资料里说地址总线和数据总线一致,这种说法也是错的,一个是物理上CPU能辨别的存储单元个数,一个是程序逻辑上能辨别的地址单元个数,两者没直接联系。以x86系列处理器为例,字长和外部数据总线及地址线可以各不相同(见下图)。
作者:papadogbl https://www.bilibili.com/read/cv19325810/ 出处:bilibili
滑动窗口其实就是特殊的双指针。
需要明白什么时候能用滑动窗口:
难点和关键在于:
本文转载完善自Hutool:一行代码搞定数据脱敏 - 京东云开发者。
数据脱敏百度百科中是这样定义的:
数据脱敏,指对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。这样就可以在开发、测试和其它非生产环境以及外包环境中安全地使用脱敏后的真实数据集。在涉及客户安全数据或者一些商业性敏感数据的情况下,在不违反系统规则条件下,对真实数据进行改造并提供测试使用,如身份证号、手机号、卡号、客户号等个人信息都需要进行数据脱敏。是数据库安全技术之一。
总的来说,数据脱敏是指对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。
在数据脱敏过程中,通常会采用不同的算法和技术,以根据不同的需求和场景对数据进行处理。例如,对于身份证号码,可以使用掩码算法(masking)将前几位数字保留,其他位用 “X” 或 “*“ 代替;对于姓名,可以使用伪造(pseudonymization)算法,将真实姓名替换成随机生成的假名。
常用脱敏规则是为了保护敏感数据的安全性,在处理和存储敏感数据时对其进行变换或修改。
下面是几种常见的脱敏规则:
Hutool 一个 Java 基础工具类,对文件、流、加密解密、转码、正则、线程、XML 等 JDK 方法进行封装,组成各种 Util 工具类,同时提供以下组件:
| 模块 | 介绍 |
|---|---|
| hutool-aop | JDK 动态代理封装,提供非 IOC 下的切面支持 |
| hutool-bloomFilter | 布隆过滤,提供一些 Hash 算法的布隆过滤 |
| hutool-cache | 简单缓存实现 |
| hutool-core | 核心,包括 Bean 操作、日期、各种 Util 等 |
| hutool-cron | 定时任务模块,提供类 Crontab 表达式的定时任务 |
| hutool-crypto | 加密解密模块,提供对称、非对称和摘要算法封装 |
| hutool-db | JDBC 封装后的数据操作,基于 ActiveRecord 思想 |
| hutool-dfa | 基于 DFA 模型的多关键字查找 |
| hutool-extra | 扩展模块,对第三方封装(模板引擎、邮件、Servlet、二维码、Emoji、FTP、分词等) |
| hutool-http | 基于 HttpUrlConnection 的 Http 客户端封装 |
| hutool-log | 自动识别日志实现的日志门面 |
| hutool-script | 脚本执行封装,例如 Javascript |
| hutool-setting | 功能更强大的 Setting 配置文件和 Properties 封装 |
| hutool-system | 系统参数调用封装(JVM 信息等) |
| hutool-json | JSON 实现 |
| hutool-captcha | 图片验证码实现 |
| hutool-poi | 针对 POI 中 Excel 和 Word 的封装 |
| hutool-socket | 基于 Java 的 NIO 和 AIO 的 Socket 封装 |
| hutool-jwt | JSON Web Token (JWT) 封装实现 |
可以根据需求对每个模块单独引入,也可以通过引入hutool-all方式引入所有模块,本文所使用的数据脱敏工具就是在 hutool.core 模块。
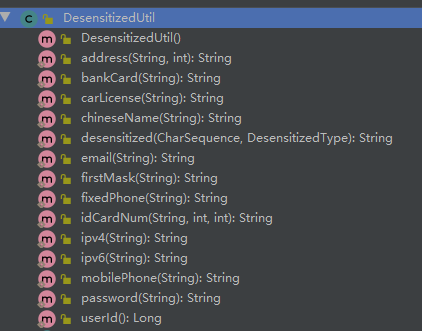
现阶段最新版本的 Hutool 支持的脱敏数据类型如下,基本覆盖了常见的敏感信息。
Hutool 提供的脱敏方法如下图所示:
注意:Hutool 脱敏是通过 * 来代替敏感信息的,具体实现是在 StrUtil.hide 方法中,如果我们想要自定义隐藏符号,则可以把 Hutool 的源码拷出来,重新实现即可。
这里以手机号、银行卡号、身份证号、密码信息的脱敏为例,下面是对应的测试代码。
1 | import cn.hutool.core.util.DesensitizedUtil; |
以上就是使用 Hutool 封装好的工具类实现数据脱敏。
现在有了数据脱敏工具类,如果前端需要显示数据数据的地方比较多,我们不可能在每个地方都调用一个工具类,这样就显得代码太冗余了,那我们如何通过注解的方式优雅的完成数据脱敏呢?
如果项目是基于 Spring Boot 的 web 项目,则可以利用 Spring Boot 自带的 jackson 自定义序列化实现。它的实现原理其实就是在 json 进行序列化渲染给前端时,进行脱敏。
第一步:脱敏策略的枚举。
1 | /** |
上面表示支持的脱敏类型。
第二步:定义一个用于脱敏的 Desensitization 注解。
@Retention (RetentionPolicy.RUNTIME):运行时生效。@Target (ElementType.FIELD):可用在字段上。@JacksonAnnotationsInside:此注解可以点进去看一下是一个元注解,主要是用户打包其他注解一起使用。@JsonSerialize:上面说到过,该注解的作用就是可自定义序列化,可以用在注解上,方法上,字段上,类上,运行时生效等等,根据提供的序列化类里面的重写方法实现自定义序列化。1 | /** |
注:只有使用了自定义的脱敏枚举 MY_RULE 的时候,开始位置和结束位置才生效。
第三步:创建自定的序列化类
这一步是我们实现数据脱敏的关键。自定义序列化类继承 JsonSerializer,实现 ContextualSerializer 接口,并重写两个方法。
1 | /** |
经过上述三步,已经完成了通过注解实现数据脱敏了,下面我们来测试一下。
首先定义一个要测试的 pojo,对应的字段加入要脱敏的策略。
1 | /** |
接下来写一个测试的 controller
1 |
|
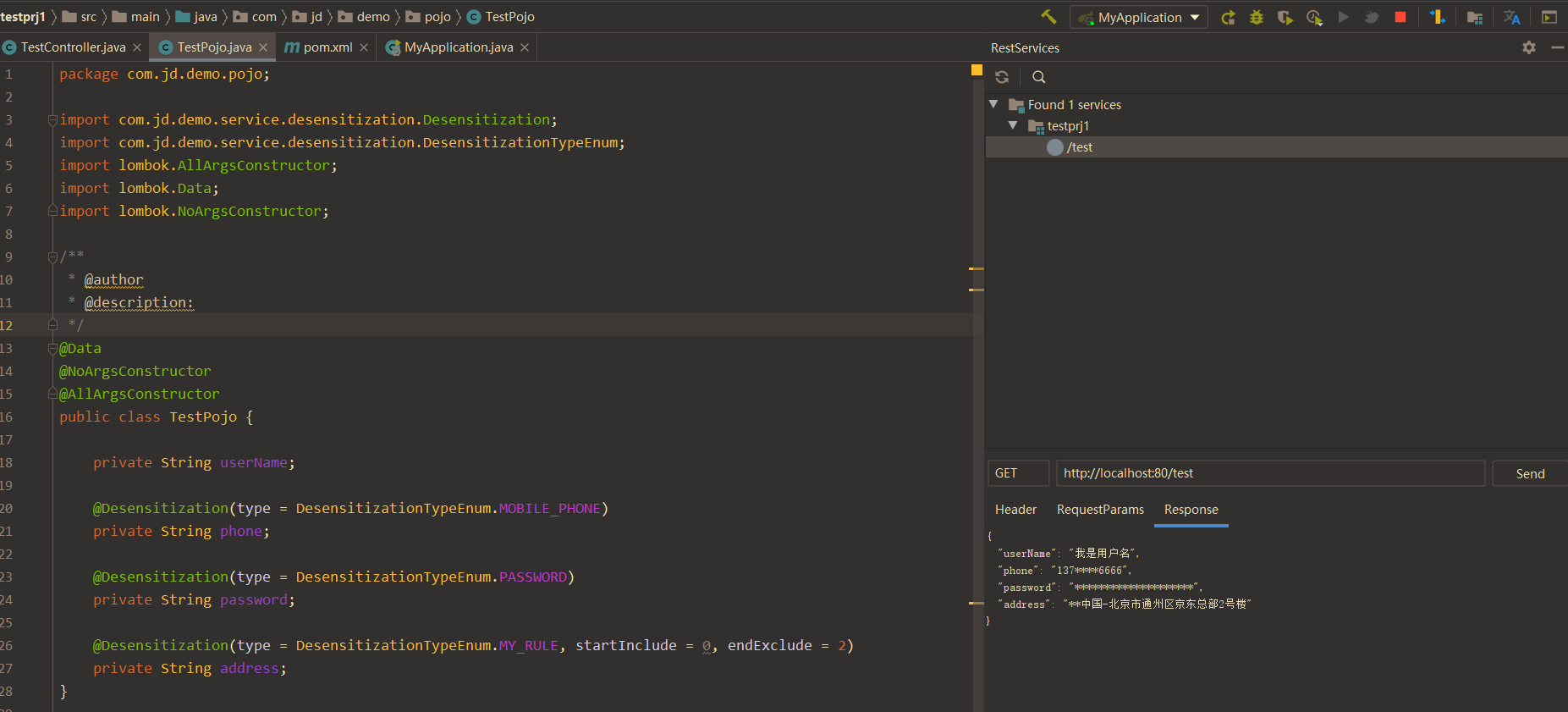
可以看到我们成功实现了数据脱敏。
ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar(计划中)这 3 款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能 。
Apache ShardingSphere 下面存在一个数据脱敏模块,此模块集成的常用的数据脱敏的功能。其基本原理是对用户输入的 SQL 进行解析拦截,并依靠用户的脱敏配置进行 SQL 的改写,从而实现对原文字段的加密及加密字段的解密。最终实现对用户无感的加解密存储、查询。
通过 Apache ShardingSphere 可以自动化&透明化数据脱敏过程,用户无需关注脱敏中间实现细节。并且,提供了多种内置、第三方(AKS)的脱敏策略,用户仅需简单配置即可使用。
官方文档地址:https://shardingsphere.apache.org/document/4.1.1/cn/features/orchestration/encrypt/ 。
平时开发 Web 项目的时候,除了默认的 Spring 自带的序列化工具,FastJson 也是一个很常用的 Spring Web Restful 接口序列化的工具。
FastJSON 实现数据脱敏的方式主要有两种:
@JSONField 实现:需要自定义一个用于脱敏的序列化的类,然后在需要脱敏的字段上通过 @JSONField 中的 serializeUsing 指定为我们自定义的序列化类型即可。ValueFilter 接口,重写 process 方法完成自定义脱敏,然后在 JSON 转换时使用自定义的转换策略。具体实现可参考这篇文章: https://juejin.cn/post/7067916686141161479。先介绍一下 MyBatis、MyBatis-Plus 和 Mybatis-Mate 这三者的关系:
Mybatis-Mate 支持敏感词脱敏,内置手机号、邮箱、银行卡号等 9 种常用脱敏规则。
1 |
|
类似于 MybatisPlus,MyBatis-Flex 也是一个 MyBatis 增强框架。MyBatis-Flex 同样提供了数据脱敏功能,并且是可以免费使用的。
MyBatis-Flex 提供了 @ColumnMask() 注解,以及内置的 9 种脱敏规则,开箱即用:
1 | /** |
使用示例:
1 |
|
如果这些内置的脱敏规则不满足你的要求的话,你还可以自定义脱敏规则。
1、通过 MaskManager 注册新的脱敏规则:
1 | MaskManager.registerMaskProcessor("自定义规则名称" |
2、使用自定义的脱敏规则
1 |
|
并且,对于需要跳过脱密处理的场景,例如进入编辑页面编辑用户数据,MyBatis-Flex 也提供了对应的支持:
MaskManager#execWithoutMask**(推荐):该方法使用了模版方法设计模式,保障跳过脱敏处理并执行相关逻辑后自动恢复脱敏处理。MaskManager#skipMask**:跳过脱敏处理。MaskManager#restoreMask**:恢复脱敏处理,确保后续的操作继续使用脱敏逻辑。MaskManager#execWithoutMask方法实现如下:
1 | public static <T> T execWithoutMask(Supplier<T> supplier) { |
MaskManager 的skipMask和restoreMask方法一般配套使用,推荐try{...}finally{...}模式。
这篇文章主要介绍了:
数组(Array) 是一种很常见的数据结构。它由相同类型的元素(element)组成,并且是使用一块连续的内存来存储。
我们直接可以利用元素的索引(index)可以计算出该元素对应的存储地址。
数组的特点是:提供随机访问 并且容量有限。
1 | 假如数组的长度为 n。 |
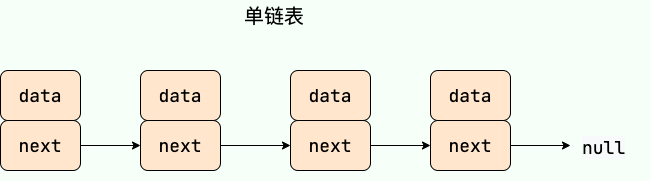
链表(LinkedList) 虽然是一种线性表,但是并不会按线性的顺序存储数据,使用的不是连续的内存空间来存储数据。
链表的插入和删除操作的复杂度为 O(1) ,只需要知道目标位置元素的上一个元素即可。但是,在查找一个节点或者访问特定位置的节点的时候复杂度为 O(n) 。
使用链表结构可以克服数组需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但链表不会节省空间,相比于数组会占用更多的空间,因为链表中每个节点存放的还有指向其他节点的指针。除此之外,链表不具有数组随机读取的优点。
常见链表分类:
1 | 假如链表中有n个元素。 |
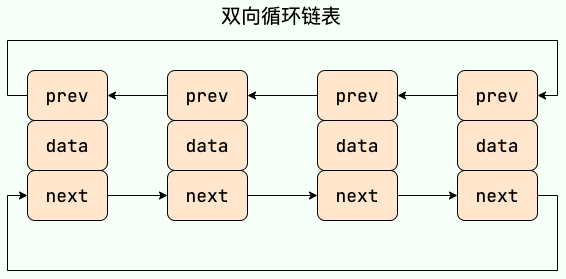
单链表 单向链表只有一个方向,结点只有一个后继指针 next 指向后面的节点。因此,链表这种数据结构通常在物理内存上是不连续的。我们习惯性地把第一个结点叫作头结点,链表通常有一个不保存任何值的 head 节点(头结点),通过头结点我们可以遍历整个链表。尾结点通常指向 null。
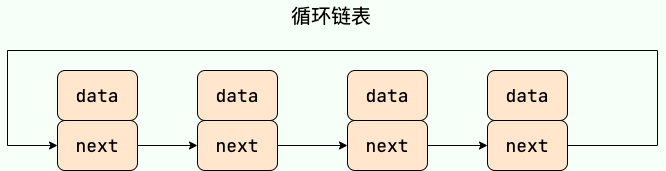
循环链表 其实是一种特殊的单链表,和单链表不同的是循环链表的尾结点不是指向 null,而是指向链表的头结点。
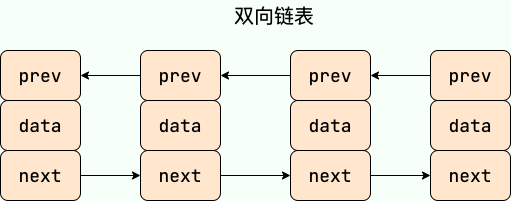
双向链表 包含两个指针,一个 prev 指向前一个节点,一个 next 指向后一个节点。
双向循环链表 最后一个节点的 next 指向 head,而 head 的 prev 指向最后一个节点,构成一个环。
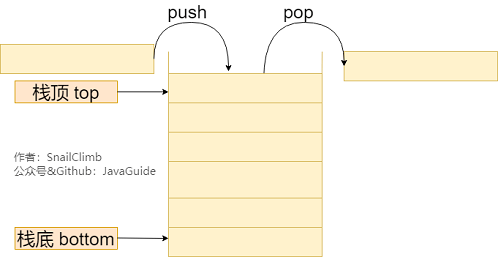
栈 (Stack) 只允许在有序的线性数据集合的一端(称为栈顶 top)进行加入数据(push)和移除数据(pop)。因而按照 后进先出(LIFO, Last In First Out) 的原理运作。在栈中,push 和 pop 的操作都发生在栈顶。
栈常用一维数组或链表来实现,用数组实现的栈叫作 顺序栈 ,用链表实现的栈叫作 链式栈 。
1 | 假设堆栈中有n个元素。 |
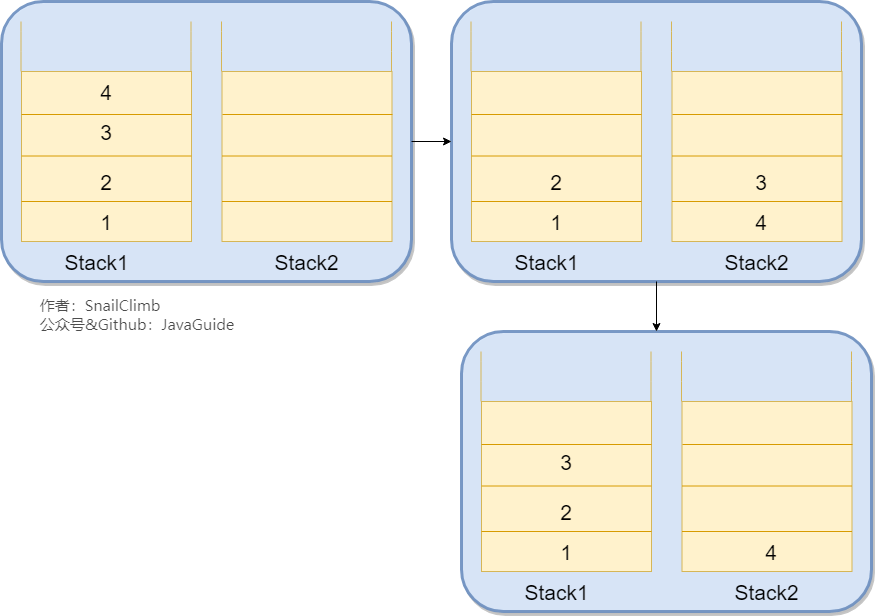
当我们我们要处理的数据只涉及在一端插入和删除数据,并且满足 后进先出(LIFO, Last In First Out) 的特性时,我们就可以使用栈这个数据结构。
我们只需要使用两个栈(Stack1 和 Stack2)和就能实现这个功能。比如你按顺序查看了 1,2,3,4 这四个页面,我们依次把 1,2,3,4 这四个页面压入 Stack1 中。当你想回头看 2 这个页面的时候,你点击回退按钮,我们依次把 4,3 这两个页面从 Stack1 弹出,然后压入 Stack2 中。假如你又想回到页面 3,你点击前进按钮,我们将 3 页面从 Stack2 弹出,然后压入到 Stack1 中。示例图如下:
给定一个只包括
'(',')','{','}','[',']'的字符串,判断该字符串是否有效。有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
比如 “()”、”()[]{}”、”{[]}” 都是有效字符串,而 “(]”、”([)]” 则不是。
这个问题实际是 Leetcode 的一道题目,我们可以利用栈 Stack 来解决这个问题。
Map 中,这一点应该毋容置疑;stack中,否则将stack 的栈顶元素与这个括号做比较,如果不相等就直接返回 false。遍历结束,如果stack为空,返回 true。1 | public boolean isValid(String s){ |
将字符串中的每个字符先入栈再出栈就可以了。
最后一个被调用的函数必须先完成执行,符合栈的 后进先出(LIFO, Last In First Out) 特性。
例如递归函数调用可以通过栈来实现,每次递归调用都会将参数和返回地址压栈。
在深度优先搜索过程中,栈被用来保存搜索路径,以便回溯到上一层。
栈既可以通过数组实现,也可以通过链表来实现。不管基于数组还是链表,入栈、出栈的时间复杂度都为 O(1)。
下面我们使用数组来实现一个栈,并且这个栈具有push()、pop()(返回栈顶元素并出栈)、peek() (返回栈顶元素不出栈)、isEmpty()、size()这些基本的方法。
提示:每次入栈之前先判断栈的容量是否够用,如果不够用就用
Arrays.copyOf()进行扩容;
1 | public class MyStack { |
验证
1 | MyStack myStack = new MyStack(3); |
队列(Queue) 是 先进先出 (FIFO,First In, First Out) 的线性表。在具体应用中通常用链表或者数组来实现,用数组实现的队列叫作 顺序队列 ,用链表实现的队列叫作 链式队列 。队列只允许在后端(rear)进行插入操作也就是入队 enqueue,在前端(front)进行删除操作也就是出队 dequeue
队列的操作方式和堆栈类似,唯一的区别在于队列只允许新数据在后端进行添加。
1 | 假设队列中有n个元素。 |

单队列就是常见的队列, 每次添加元素时,都是添加到队尾。单队列又分为 顺序队列(数组实现) 和 链式队列(链表实现)。
顺序队列存在“假溢出”的问题也就是明明有位置却不能添加的情况。
假设下图是一个顺序队列,我们将前两个元素 1,2 出队,并入队两个元素 7,8。当进行入队、出队操作的时候,front 和 rear 都会持续往后移动,当 rear 移动到最后的时候,我们无法再往队列中添加数据,即使数组中还有空余空间,这种现象就是 ”假溢出“ 。除了假溢出问题之外,如下图所示,当添加元素 8 的时候,rear 指针移动到数组之外(越界)。
为了避免当只有一个元素的时候,队头和队尾重合使处理变得麻烦,所以引入两个指针,front 指针指向对头元素,rear 指针指向队列最后一个元素的下一个位置,这样当 front 等于 rear 时,此队列不是还剩一个元素,而是空队列。——From 《大话数据结构》
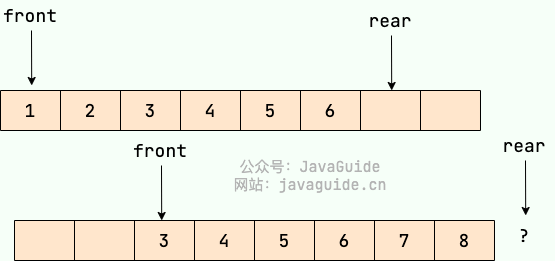
循环队列可以解决顺序队列的假溢出和越界问题。解决办法就是:从头开始,这样也就会形成头尾相接的循环,这也就是循环队列名字的由来。
还是用上面的图,我们将 rear 指针指向数组下标为 0 的位置就不会有越界问题了。当我们再向队列中添加元素的时候, rear 向后移动。
顺序队列中,我们说 front==rear 的时候队列为空,循环队列中则不一样,也可能为满,如上图所示。解决办法有两种:
flag,当 front==rear 并且 flag=0 的时候队列为空,当front==rear 并且 flag=1 的时候队列为满。front==rear ,队列满的时候,我们保证数组还有一个空闲的位置,rear 就指向这个空闲位置,如下图所示,那么现在判断队列是否为满的条件就是:(rear+1) % QueueSize==front 。双端队列 (Deque) 是一种在队列的两端都可以进行插入和删除操作的队列,相比单队列来说更加灵活。
一般来说,我们可以对双端队列进行 addFirst、addLast、removeFirst 和 removeLast 操作。
优先队列 (Priority Queue) 从底层结构上来讲并非线性的数据结构,它一般是由堆来实现的。
关于堆的具体实现可以看堆这一节。
总而言之,不论我们进行什么操作,优先队列都能按照某种排序方式进行一系列堆的相关操作,从而保证整个集合的有序性。
虽然优先队列的底层并非严格的线性结构,但是在我们使用的过程中,我们是感知不到堆的,从使用者的眼中优先队列可以被认为是一种线性的数据结构:一种会自动排序的线性队列。
当我们需要按照一定顺序来处理数据的时候可以考虑使用队列这个数据结构。
FixedThreadPool 使用无界队列 LinkedBlockingQueue。但是有界队列就不一样了,当队列满的话后面再有任务/请求就会拒绝,在 Java 中的体现就是会抛出java.util.concurrent.RejectedExecutionException 异常。push、pop 和 peek),并且在 Deque 接口中已经实现了相关方法。Stack 类已经和 Vector 一样被遗弃,现在在 Java 中普遍使用双端队列(Deque)来实现栈。题目来源于:牛客题霸 - SQL 进阶挑战
较难或者困难的题目可以根据自身实际情况和面试需要来决定是否要跳过。
描述:
现有试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分),数据如下:
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
| 3 | 1001 | 9001 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
请统计有未完成状态的试卷的未完成数 incomplete_cnt 和未完成率 incomplete_rate。由示例数据结果输出如下:
| exam_id | incomplete_cnt | complete_rate |
|---|---|---|
| 9001 | 1 | 0.333 |
解释:试卷 9001 有 3 次被作答的记录,其中两次完成,1 次未完成,因此未完成数为 1,未完成率为 0.333(保留 3 位小数)
思路:
这题只需要注意一个是有条件限制,一个是没条件限制的;要么分别查询条件,然后合并;要么直接在 select 里面进行条件判断。
答案:
写法 1:
1 | SELECT exam_id, |
写法 2:
1 | SELECT exam_id, |
两种写法都可以,只有中间的写法不一样,一个是对符合条件的才COUNT,一个是直接上IF,后者更为直观,最后这个having解释一下, 无论是 complete_rate 还是 incomplete_cnt,只要不为 0 即可,不为 0 就意味着有未完成的。
描述:
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间),数据如下:
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 号 | 10 | 0 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 2100 | 6 | 算法 | 2020-01-01 10:00:00 |
试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间),数据如下:
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
| 2 | 9002 | SQL | easy | 60 | 2020-01-01 10:00:00 |
| 3 | 9004 | 算法 | medium | 80 | 2020-01-01 10:00:00 |
试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分),数据如下:
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
| 4 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
| 5 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 7 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
请输出每个 0 级用户所有的高难度试卷考试平均用时和平均得分,未完成的默认试卷最大考试时长和 0 分处理。由示例数据结果输出如下:
| uid | avg_score | avg_time_took |
|---|---|---|
| 1001 | 33 | 36.7 |
解释:0 级用户有 1001,高难度试卷有 9001,1001 作答 9001 的记录有 3 条,分别用时 20 分钟、未完成(试卷时长 60 分钟)、30 分钟(未满 31 分钟),分别得分为 80 分、未完成(0 分处理)、20 分。因此他的平均用时为 110/3=36.7(保留一位小数),平均得分为 33 分(取整)
思路:这题用IF是判断的最方便的,因为涉及到 NULL 值的判断。当然 case when也可以,大同小异。这题的难点就在于空值的处理,其他的这些查询条件什么的,我相信难不倒大家。
答案:
1 | SELECT UID, |
描述:
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 号 | 1000 | 2 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 进击的 3 号 | 2200 | 5 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客 4 号 | 2500 | 6 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 牛客 5 号 | 3000 | 7 | C++ | 2020-01-01 10:00:00 |
试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
| 4 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 5 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
| 11 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 81 |
| 12 | 1002 | 9002 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
| 13 | 1002 | 9002 | 2020-02-02 12:11:01 | 2020-02-02 12:31:01 | 83 |
| 7 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
| 16 | 1002 | 9001 | 2021-09-06 12:01:01 | 2021-09-06 12:21:01 | 80 |
| 17 | 1002 | 9001 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
| 18 | 1002 | 9001 | 2021-09-07 12:01:01 | (NULL) | (NULL) |
| 8 | 1003 | 9003 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
| 9 | 1003 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 89 |
| 10 | 1004 | 9002 | 2021-08-06 12:01:01 | (NULL) | (NULL) |
| 14 | 1005 | 9001 | 2021-02-01 11:01:01 | 2021-02-01 11:31:01 | 84 |
| 15 | 1006 | 9001 | 2021-02-01 11:01:01 | 2021-02-01 11:31:01 | 84 |
题目练习记录表 practice_record(uid 用户 ID, question_id 题目 ID, submit_time 提交时间, score 得分):
| id | uid | question_id | submit_time | score |
|---|---|---|---|---|
| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
| 5 | 1003 | 8002 | 2021-09-01 19:38:01 | 80 |
请找到昵称以『牛客』开头『号』结尾、成就值在 1200~2500 之间,且最近一次活跃(答题或作答试卷)在 2021 年 9 月的用户信息。
由示例数据结果输出如下:
| uid | nick_name | achievement |
|---|---|---|
| 1002 | 牛客 2 号 | 1200 |
解释:昵称以『牛客』开头『号』结尾且成就值在 1200~2500 之间的有 1002、1004;
1002 最近一次试卷区活跃为 2021 年 9 月,最近一次题目区活跃为 2021 年 9 月;1004 最近一次试卷区活跃为 2021 年 8 月,题目区未活跃。
因此最终满足条件的只有 1002。
思路:
先根据条件列出主要查询语句
昵称以『牛客』开头『号』结尾: nick_name LIKE "牛客%号"
成就值在 1200~2500 之间:achievement BETWEEN 1200 AND 2500
第三个条件因为限定了为 9 月,所以直接写就行:( date_format( record.submit_time, '%Y%m' )= 202109 OR date_format( pr.submit_time, '%Y%m' )= 202109 )
答案:
1 | SELECT DISTINCT u_info.uid, |
描述:
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 号 | 1900 | 2 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 牛客 3 号 ♂ | 2200 | 5 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客 4 号 | 2500 | 6 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 牛客 555 号 | 2000 | 7 | C++ | 2020-01-01 10:00:00 |
| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间):
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | C++ | hard | 60 | 2020-01-01 10:00:00 |
| 2 | 9002 | c# | hard | 80 | 2020-01-01 10:00:00 |
| 3 | 9003 | SQL | medium | 70 | 2020-01-01 10:00:00 |
试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
| 4 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
| 5 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 11 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 81 |
| 16 | 1002 | 9001 | 2021-09-06 12:01:01 | 2021-09-06 12:21:01 | 80 |
| 17 | 1002 | 9001 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
| 18 | 1002 | 9001 | 2021-09-07 12:01:01 | (NULL) | (NULL) |
| 7 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
| 12 | 1002 | 9002 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
| 13 | 1002 | 9002 | 2020-02-02 12:11:01 | 2020-02-02 12:31:01 | 83 |
| 9 | 1003 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 89 |
| 8 | 1003 | 9003 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
| 10 | 1004 | 9002 | 2021-08-06 12:01:01 | (NULL) | (NULL) |
| 14 | 1005 | 9001 | 2021-02-01 11:01:01 | 2021-02-01 11:31:01 | 84 |
| 15 | 1006 | 9001 | 2021-02-01 11:01:01 | 2021-09-01 11:31:01 | 84 |
找到昵称以”牛客”+纯数字+”号”或者纯数字组成的用户对于字母 c 开头的试卷类别(如 C,C++,c#等)的已完成的试卷 ID 和平均得分,按用户 ID、平均分升序排序。由示例数据结果输出如下:
| uid | exam_id | avg_score |
|---|---|---|
| 1002 | 9001 | 81 |
| 1002 | 9002 | 85 |
| 1005 | 9001 | 84 |
| 1006 | 9001 | 84 |
解释:昵称满足条件的用户有 1002、1004、1005、1006;
c 开头的试卷有 9001、9002;
满足上述条件的作答记录中,1002 完成 9001 的得分有 81、80,平均分为 81(80.5 取整四舍五入得 81);
1002 完成 9002 的得分有 90、82、83,平均分为 85;
思路:
还是老样子,既然给出了条件,就先把各个条件先写出来
找到昵称以”牛客”+纯数字+”号”或者纯数字组成的用户: 我最开始是这么写的:nick_name LIKE '牛客%号' OR nick_name REGEXP '^[0-9]+$',如果表中有个 “牛客 H 号” ,那也能通过。
所以这里还得用正则: nick_name LIKE '^牛客[0-9]+号'
对于字母 c 开头的试卷类别: e_info.tag LIKE 'c%' 或者 tag regexp '^c|^C' 第一个也能匹配到大写 C
答案:
1 | SELECT UID, |
描述:
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 号 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 进击的 3 号 | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客 4 号 | 25 | 0 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 牛客 555 号 | 2000 | 7 | C++ | 2020-01-01 10:00:00 |
| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
| 4 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 5 | 1001 | 9003 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
| 6 | 1001 | 9004 | 2021-09-03 12:01:01 | (NULL) | (NULL) |
| 7 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 99 |
| 8 | 1002 | 9003 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
| 9 | 1002 | 9003 | 2020-02-02 12:11:01 | (NULL) | (NULL) |
| 10 | 1002 | 9002 | 2021-05-05 18:01:01 | (NULL) | (NULL) |
| 11 | 1002 | 9001 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
| 12 | 1003 | 9003 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
| 13 | 1003 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 89 |
请你筛选表中的数据,当有任意一个 0 级用户未完成试卷数大于 2 时,输出每个 0 级用户的试卷未完成数和未完成率(保留 3 位小数);若不存在这样的用户,则输出所有有作答记录的用户的这两个指标。结果按未完成率升序排序。
由示例数据结果输出如下:
| uid | incomplete_cnt | incomplete_rate |
|---|---|---|
| 1004 | 0 | 0.000 |
| 1003 | 1 | 0.500 |
| 1001 | 4 | 0.667 |
解释:0 级用户有 1001、1003、1004;他们作答试卷数和未完成数分别为:6:4、2:1、0:0;
存在 1001 这个 0 级用户未完成试卷数大于 2,因此输出这三个用户的未完成数和未完成率(1004 未作答过试卷,未完成率默认填 0,保留 3 位小数后是 0.000);
结果按照未完成率升序排序。
附:如果 1001 不满足『未完成试卷数大于 2』,则需要输出 1001、1002、1003 的这两个指标,因为试卷作答记录表里只有这三个用户的作答记录。
思路:
先把可能满足条件“0 级用户未完成试卷数大于 2”的 SQL 写出来
1 | SELECT ui.uid UID |
然后再分别写出两种情况的 SQL 查询语句:
情况 1. 查询存在条件要求的 0 级用户的试卷未完成率
1 | SELECT |
情况 2. 查询不存在条件要求时所有有作答记录的 yong 用户的试卷未完成率
1 | SELECT |
拼在一起,就是答案
1 | WITH host_user AS |
V2 版本(根据上面做出的改进,答案缩短了,逻辑更强):
1 | SELECT |
描述:
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 号 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 牛客 3 号 ♂ | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客 4 号 | 25 | 0 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 牛客 555 号 | 2000 | 7 | C++ | 2020-01-01 10:00:00 |
| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 75 |
| 4 | 1001 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:11:01 | 60 |
| 5 | 1001 | 9003 | 2021-09-02 12:01:01 | 2021-09-02 12:41:01 | 90 |
| 6 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
| 7 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
| 8 | 1001 | 9004 | 2021-09-03 12:01:01 | (NULL) | (NULL) |
| 9 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 99 |
| 10 | 1002 | 9003 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
| 11 | 1002 | 9003 | 2020-02-02 12:11:01 | 2020-02-02 12:41:01 | 76 |
为了得到用户试卷作答的定性表现,我们将试卷得分按分界点[90,75,60]分为优良中差四个得分等级(分界点划分到左区间),请统计不同用户等级的人在完成过的试卷中各得分等级占比(结果保留 3 位小数),未完成过试卷的用户无需输出,结果按用户等级降序、占比降序排序。
由示例数据结果输出如下:
| level | score_grade | ratio |
|---|---|---|
| 3 | 良 | 0.667 |
| 3 | 优 | 0.333 |
| 0 | 良 | 0.500 |
| 0 | 中 | 0.167 |
| 0 | 优 | 0.167 |
| 0 | 差 | 0.167 |
解释:完成过试卷的用户有 1001、1002;完成了的试卷对应的用户等级和分数等级如下:
| uid | exam_id | score | level | score_grade |
|---|---|---|---|---|
| 1001 | 9001 | 80 | 0 | 良 |
| 1001 | 9002 | 75 | 0 | 良 |
| 1001 | 9002 | 60 | 0 | 中 |
| 1001 | 9003 | 90 | 0 | 优 |
| 1001 | 9001 | 20 | 0 | 差 |
| 1001 | 9002 | 89 | 0 | 良 |
| 1002 | 9001 | 99 | 3 | 优 |
| 1002 | 9003 | 82 | 3 | 良 |
| 1002 | 9003 | 76 | 3 | 良 |
因此 0 级用户(只有 1001)的各分数等级比例为:优 1/6,良 1/6,中 1/6,差 3/6;3 级用户(只有 1002)各分数等级比例为:优 1/3,良 2/3。结果保留 3 位小数。
思路:
先把 “将试卷得分按分界点[90,75,60]分为优良中差四个得分等级”这个条件写出来,这里可以用到case when
1 | CASE |
这题的关键点就在于这,其他剩下的就是条件拼接了
答案:
1 | SELECT a.LEVEL, |
描述:
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 号 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-02-01 10:00:00 |
| 3 | 1003 | 牛客 3 号 ♂ | 22 | 0 | 算法 | 2020-01-02 10:00:00 |
| 4 | 1004 | 牛客 4 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
| 5 | 1005 | 牛客 555 号 | 4000 | 7 | C++ | 2020-01-11 10:00:00 |
| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-11-01 10:00:00 |
请从中找到注册时间最早的 3 个人。由示例数据结果输出如下:
| uid | nick_name | register_time |
|---|---|---|
| 1001 | 牛客 1 | 2020-01-01 10:00:00 |
| 1003 | 牛客 3 号 ♂ | 2020-01-02 10:00:00 |
| 1004 | 牛客 4 号 | 2020-01-02 11:00:00 |
解释:按注册时间排序后选取前三名,输出其用户 ID、昵称、注册时间。
答案:
1 | SELECT uid, nick_name, register_time |
描述:现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 牛客 3 号 ♂ | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客 4 号 | 25 | 0 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 牛客 555 号 | 4000 | 7 | 算法 | 2020-01-11 10:00:00 |
| 6 | 1006 | 牛客 6 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
| 7 | 1007 | 牛客 7 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
| 8 | 1008 | 牛客 8 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
| 9 | 1009 | 牛客 9 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
| 10 | 1010 | 牛客 10 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
| 11 | 1011 | 666666 | 3000 | 6 | C++ | 2020-01-02 10:00:00 |
试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间):
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | 算法 | hard | 60 | 2020-01-01 10:00:00 |
| 2 | 9002 | 算法 | hard | 80 | 2020-01-01 10:00:00 |
| 3 | 9003 | SQL | medium | 70 | 2020-01-01 10:00:00 |
试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
| 2 | 1002 | 9003 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 81 |
| 3 | 1002 | 9002 | 2020-01-01 12:11:01 | 2020-01-01 12:31:01 | 83 |
| 4 | 1003 | 9002 | 2020-01-01 19:01:01 | 2020-01-01 19:30:01 | 75 |
| 5 | 1004 | 9002 | 2020-01-01 12:01:01 | 2020-01-01 12:11:01 | 60 |
| 6 | 1005 | 9002 | 2020-01-01 12:01:01 | 2020-01-01 12:41:01 | 90 |
| 7 | 1006 | 9001 | 2020-01-02 19:01:01 | 2020-01-02 19:32:00 | 20 |
| 8 | 1007 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:40:01 | 89 |
| 9 | 1008 | 9003 | 2020-01-02 12:01:01 | 2020-01-02 12:20:01 | 99 |
| 10 | 1008 | 9001 | 2020-01-02 12:01:01 | 2020-01-02 12:31:01 | 98 |
| 11 | 1009 | 9002 | 2020-01-02 12:01:01 | 2020-01-02 12:31:01 | 82 |
| 12 | 1010 | 9002 | 2020-01-02 12:11:01 | 2020-01-02 12:41:01 | 76 |
| 13 | 1011 | 9001 | 2020-01-02 10:01:01 | 2020-01-02 10:31:01 | 89 |
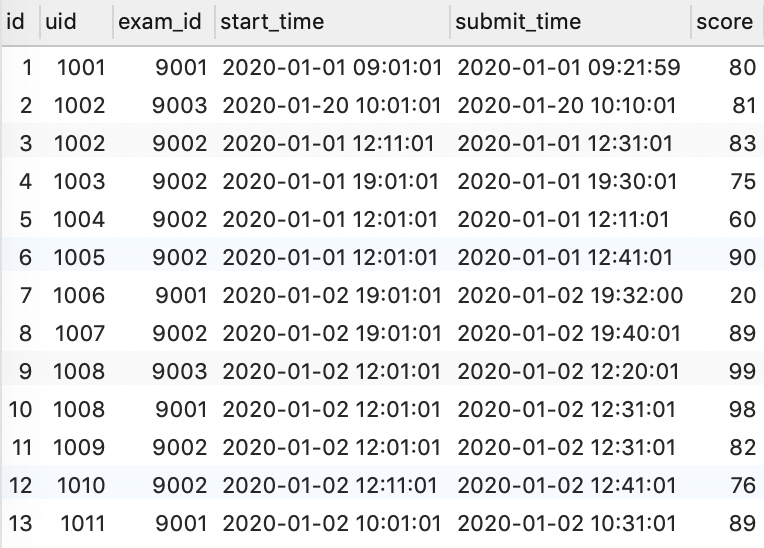
找到求职方向为算法工程师,且注册当天就完成了算法类试卷的人,按参加过的所有考试最高得分排名。排名榜很长,我们将采用分页展示,每页 3 条,现在需要你取出第 3 页(页码从 1 开始)的人的信息。
由示例数据结果输出如下:
| uid | level | register_time | max_score |
|---|---|---|---|
| 1010 | 0 | 2020-01-02 11:00:00 | 76 |
| 1003 | 0 | 2020-01-01 10:00:00 | 75 |
| 1004 | 0 | 2020-01-01 11:00:00 | 60 |
解释:除了 1011 其他用户的求职方向都为算法工程师;算法类试卷有 9001 和 9002,11 个用户注册当天都完成了算法类试卷;计算他们的所有考试最大分时,只有 1002 和 1008 完成了两次考试,其他人只完成了一场考试,1002 两场考试最高分为 81,1008 最高分为 99。
按最高分排名如下:
| uid | level | register_time | max_score |
|---|---|---|---|
| 1008 | 0 | 2020-01-02 11:00:00 | 99 |
| 1005 | 7 | 2020-01-01 10:00:00 | 90 |
| 1007 | 0 | 2020-01-02 11:00:00 | 89 |
| 1002 | 3 | 2020-01-01 10:00:00 | 83 |
| 1009 | 0 | 2020-01-02 11:00:00 | 82 |
| 1001 | 0 | 2020-01-01 10:00:00 | 80 |
| 1010 | 0 | 2020-01-02 11:00:00 | 76 |
| 1003 | 0 | 2020-01-01 10:00:00 | 75 |
| 1004 | 0 | 2020-01-01 11:00:00 | 60 |
| 1006 | 0 | 2020-01-02 11:00:00 | 20 |
每页 3 条,第三页也就是第 7~9 条,返回 1010、1003、1004 的行记录即可。
思路:
每页三条,即需要取出第三页的人的信息,要用到limit
统计求职方向为算法工程师且注册当天就完成了算法类试卷的人的信息和每次记录的得分,先求满足条件的用户,后用 left join 做连接查找信息和每次记录的得分
答案:
1 | SELECT t1.uid, |
描述:现有试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间):
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | 算法 | hard | 60 | 2021-01-01 10:00:00 |
| 2 | 9002 | 算法 | hard | 80 | 2021-01-01 10:00:00 |
| 3 | 9003 | SQL | medium | 70 | 2021-01-01 10:00:00 |
| 4 | 9004 | 算法,medium,80 | 0 | 2021-01-01 10:00:00 |
录题同学有一次手误将部分记录的试题类别 tag、难度、时长同时录入到了 tag 字段,请帮忙找出这些录错了的记录,并拆分后按正确的列类型输出。
由示例数据结果输出如下:
| exam_id | tag | difficulty | duration |
|---|---|---|---|
| 9004 | 算法 | medium | 80 |
思路:
先来学习下本题要用到的函数
SUBSTRING_INDEX 函数用于提取字符串中指定分隔符的部分。它接受三个参数:原始字符串、分隔符和指定要返回的部分的数量。
以下是 SUBSTRING_INDEX 函数的语法:
1 | SUBSTRING_INDEX(str, delimiter, count) |
str:要进行分割的原始字符串。delimiter:用作分割的字符串或字符。count:指定要返回的部分的数量。count 大于 0,则返回从左边开始的前 count 个部分(以分隔符为界)。count 小于 0,则返回从右边开始的前 count 个部分(以分隔符为界),即从右侧向左计数。下面是一些示例,演示了 SUBSTRING_INDEX 函数的使用:
提取字符串中的第一个部分:
1 | SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', 1); |
提取字符串中的最后一个部分:
1 | SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', -1); |
提取字符串中的前两个部分:
1 | SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', 2); |
提取字符串中的最后两个部分:
1 | SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', -2); |
答案:
1 | SELECT |
描述:现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 牛客 3 号 ♂ | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客 4 号 | 25 | 0 | 算法 | 2020-01-01 11:00:00 |
| 5 | 1005 | 牛客 5678901234 号 | 4000 | 7 | 算法 | 2020-01-11 10:00:00 |
| 6 | 1006 | 牛客 67890123456789 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
有的用户的昵称特别长,在一些展示场景会导致样式混乱,因此需要将特别长的昵称转换一下再输出,请输出字符数大于 10 的用户信息,对于字符数大于 13 的用户输出前 10 个字符然后加上三个点号:『…』。
由示例数据结果输出如下:
| uid | nick_name |
|---|---|
| 1005 | 牛客 5678901234 号 |
| 1006 | 牛客 67890123… |
解释:字符数大于 10 的用户有 1005 和 1006,长度分别为 13、17;因此需要对 1006 的昵称截断输出。
思路:
这题涉及到字符的计算,要计算字符串的字符数(即字符串的长度),可以使用 LENGTH 函数或 CHAR_LENGTH 函数。这两个函数的区别在于对待多字节字符的方式。
LENGTH 函数:它返回给定字符串的字节数。对于包含多字节字符的字符串,每个字符都会被当作一个字节来计算。示例:
1 | SELECT LENGTH('你好'); -- 输出结果:6,因为 '你好' 中的每个汉字每个占3个字节 |
CHAR_LENGTH 函数:它返回给定字符串的字符数。对于包含多字节字符的字符串,每个字符会被当作一个字符来计算。示例:
1 | SELECT CHAR_LENGTH('你好'); -- 输出结果:2,因为 '你好' 中有两个字符,即两个汉字 |
答案:
1 | SELECT |
描述:
现有试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间):
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | 算法 | hard | 60 | 2021-01-01 10:00:00 |
| 2 | 9002 | C++ | hard | 80 | 2021-01-01 10:00:00 |
| 3 | 9003 | C++ | hard | 80 | 2021-01-01 10:00:00 |
| 4 | 9004 | sql | medium | 70 | 2021-01-01 10:00:00 |
| 5 | 9005 | C++ | hard | 80 | 2021-01-01 10:00:00 |
| 6 | 9006 | C++ | hard | 80 | 2021-01-01 10:00:00 |
| 7 | 9007 | C++ | hard | 80 | 2021-01-01 10:00:00 |
| 8 | 9008 | SQL | medium | 70 | 2021-01-01 10:00:00 |
| 9 | 9009 | SQL | medium | 70 | 2021-01-01 10:00:00 |
| 10 | 9010 | SQL | medium | 70 | 2021-01-01 10:00:00 |
试卷作答信息表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 80 |
| 2 | 1002 | 9003 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 81 |
| 3 | 1002 | 9002 | 2020-02-01 12:11:01 | 2020-02-01 12:31:01 | 83 |
| 4 | 1003 | 9002 | 2020-03-01 19:01:01 | 2020-03-01 19:30:01 | 75 |
| 5 | 1004 | 9002 | 2020-03-01 12:01:01 | 2020-03-01 12:11:01 | 60 |
| 6 | 1005 | 9002 | 2020-03-01 12:01:01 | 2020-03-01 12:41:01 | 90 |
| 7 | 1006 | 9001 | 2020-05-02 19:01:01 | 2020-05-02 19:32:00 | 20 |
| 8 | 1007 | 9003 | 2020-01-02 19:01:01 | 2020-01-02 19:40:01 | 89 |
| 9 | 1008 | 9004 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
| 10 | 1008 | 9001 | 2020-02-02 12:01:01 | 2020-02-02 12:31:01 | 98 |
| 11 | 1009 | 9002 | 2020-02-02 12:01:01 | 2020-01-02 12:43:01 | 81 |
| 12 | 1010 | 9001 | 2020-01-02 12:11:01 | (NULL) | (NULL) |
| 13 | 1010 | 9001 | 2020-02-02 12:01:01 | 2020-01-02 10:31:01 | 89 |
试卷的类别 tag 可能出现大小写混乱的情况,请先筛选出试卷作答数小于 3 的类别 tag,统计将其转换为大写后对应的原本试卷作答数。
如果转换后 tag 并没有发生变化,不输出该条结果。
由示例数据结果输出如下:
| tag | answer_cnt |
|---|---|
| C++ | 6 |
解释:被作答过的试卷有 9001、9002、9003、9004,他们的 tag 和被作答次数如下:
| exam_id | tag | answer_cnt |
|---|---|---|
| 9001 | 算法 | 4 |
| 9002 | C++ | 6 |
| 9003 | c++ | 2 |
| 9004 | sql | 2 |
作答次数小于 3 的 tag 有 c++和 sql,而转为大写后只有 C++本来就有作答数,于是输出 c++转化大写后的作答次数为 6。
思路:
首先,这题有点混乱,9004 根据示例数据查出来只有 1 次,这里显示有 2 次。
先看一下大小写转换函数:
1.UPPER(s)或UCASE(s)函数可以将字符串 s 中的字母字符全部转换成大写字母;
2.LOWER(s)或者LCASE(s)函数可以将字符串 s 中的字母字符全部转换成小写字母。
难点在于相同表做连接要查询不同的值
答案:
1 | WITH a AS |
在 Java Web 程序中,Servlet主要负责接收用户请求 HttpServletRequest,在doGet(),doPost()中做相应的处理,并将回应HttpServletResponse反馈给用户。Servlet 可以设置初始化参数,供 Servlet 内部使用。一个 Servlet 类只会有一个实例,在它初始化时调用init()方法,销毁时调用destroy()方法。Servlet 需要在 web.xml 中配置(MyEclipse 中创建 Servlet 会自动配置),一个 Servlet 可以设置多个 URL 访问。Servlet 不是线程安全,因此要谨慎使用类变量。
1,需要为每个请求启动一个操作 CGI 程序的系统进程。如果请求频繁,这将会带来很大的开销。
2,需要为每个请求加载和运行一个 CGI 程序,这将带来很大的开销
3,需要重复编写处理网络协议的代码以及编码,这些工作都是非常耗时的。
1,只需要启动一个操作系统进程以及加载一个 JVM,大大降低了系统的开销
2,如果多个请求需要做同样处理的时候,这时候只需要加载一个类,这也大大降低了开销
3,所有动态加载的类可以实现对网络协议以及请求解码的共享,大大降低了工作量。
4,Servlet 能直接和 Web 服务器交互,而普通的 CGI 程序不能。Servlet 还能在各个程序之间共享数据,使数据库连接池之类的功能很容易实现。
补充:Sun Microsystems 公司在 1996 年发布 Servlet 技术就是为了和 CGI 进行竞争,Servlet 是一个特殊的 Java 程序,一个基于 Java 的 Web 应用通常包含一个或多个 Servlet 类。Servlet 不能够自行创建并执行,它是在 Servlet 容器中运行的,容器将用户的请求传递给 Servlet 程序,并将 Servlet 的响应回传给用户。通常一个 Servlet 会关联一个或多个 JSP 页面。以前 CGI 经常因为性能开销上的问题被诟病,然而 Fast CGI 早就已经解决了 CGI 效率上的问题,所以面试的时候大可不必信口开河的诟病 CGI,事实上有很多你熟悉的网站都使用了 CGI 技术。
参考:《javaweb 整合开发王者归来》P7
Servlet 接口定义了 5 个方法,其中前三个方法与 Servlet 生命周期相关:
void init(ServletConfig config) throws ServletExceptionvoid service(ServletRequest req, ServletResponse resp) throws ServletException, java.io.IOExceptionvoid destroy()java.lang.String getServletInfo()ServletConfig getServletConfig()生命周期: Web 容器加载 Servlet 并将其实例化后,Servlet 生命周期开始,容器运行其init()方法进行 Servlet 的初始化;请求到达时调用 Servlet 的service()方法,service()方法会根据需要调用与请求对应的doGet 或 doPost等方法;当服务器关闭或项目被卸载时服务器会将 Servlet 实例销毁,此时会调用 Servlet 的destroy()方法。init 方法和 destroy 方法只会执行一次,service 方法客户端每次请求 Servlet 都会执行。Servlet 中有时会用到一些需要初始化与销毁的资源,因此可以把初始化资源的代码放入 init 方法中,销毁资源的代码放入 destroy 方法中,这样就不需要每次处理客户端的请求都要初始化与销毁资源。
参考:《javaweb 整合开发王者归来》P81
这个问题在知乎上被讨论的挺火热的,地址:https://www.zhihu.com/question/28586791 。
GET 和 POST 是 HTTP 协议中两种常用的请求方法,它们在不同的场景和目的下有不同的特点和用法。一般来说,可以从以下几个方面来区分它们:
重点搞清了,两者在语义上的区别即可。不过,也有一些项目所有的请求都用 POST,这个并不是固定的,项目组达成共识即可。
Form 标签里的 method 的属性为 get 时调用 doGet(),为 post 时调用 doPost()。
转发是服务器行为,重定向是客户端行为。
转发(Forward)
通过 RequestDispatcher 对象的 forward(HttpServletRequest request,HttpServletResponse response)方法实现的。RequestDispatcher 可以通过 HttpServletRequest 的 getRequestDispatcher()方法获得。例如下面的代码就是跳转到 login_success.jsp 页面。
1 | request.getRequestDispatcher("login_success.jsp").forward(request, response); |
重定向(Redirect) 是利用服务器返回的状态码来实现的。客户端浏览器请求服务器的时候,服务器会返回一个状态码。服务器通过 HttpServletResponse 的 setStatus(int status) 方法设置状态码。如果服务器返回 301 或者 302,则浏览器会到新的网址重新请求该资源。
从地址栏显示来说
forward 是服务器请求资源,服务器直接访问目标地址的 URL,把那个 URL 的响应内容读取过来,然后把这些内容再发给浏览器.浏览器根本不知道服务器发送的内容从哪里来的,所以它的地址栏还是原来的地址.
redirect 是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址.所以地址栏显示的是新的 URL.
从数据共享来说
forward:转发页面和转发到的页面可以共享 request 里面的数据.
redirect:不能共享数据.
从运用地方来说
forward:一般用于用户登陆的时候,根据角色转发到相应的模块.
redirect:一般用于用户注销登陆时返回主页面和跳转到其它的网站等
从效率来说
forward:高.
redirect:低.
自动刷新不仅可以实现一段时间之后自动跳转到另一个页面,还可以实现一段时间之后自动刷新本页面。Servlet 中通过 HttpServletResponse 对象设置 Header 属性实现自动刷新例如:
1 | Response.setHeader("Refresh","5;URL=http://localhost:8080/servlet/example.htm"); |
其中 5 为时间,单位为秒。URL 指定就是要跳转的页面(如果设置自己的路径,就会实现每过 5 秒自动刷新本页面一次)
Servlet 不是线程安全的,多线程并发的读写会导致数据不同步的问题。 解决的办法是尽量不要定义 name 属性,而是要把 name 变量分别定义在 doGet()和 doPost()方法内。虽然使用 synchronized(name){}语句块可以解决问题,但是会造成线程的等待,不是很科学的办法。
注意:多线程的并发的读写 Servlet 类属性会导致数据不同步。但是如果只是并发地读取属性而不写入,则不存在数据不同步的问题。因此 Servlet 里的只读属性最好定义为 final 类型的。
参考:《javaweb 整合开发王者归来》P92
其实这个问题在上面已经阐述过了,Servlet 是一个特殊的 Java 程序,它运行于服务器的 JVM 中,能够依靠服务器的支持向浏览器提供显示内容。JSP 本质上是 Servlet 的一种简易形式,JSP 会被服务器处理成一个类似于 Servlet 的 Java 程序,可以简化页面内容的生成。Servlet 和 JSP 最主要的不同点在于,Servlet 的应用逻辑是在 Java 文件中,并且完全从表示层中的 HTML 分离开来。而 JSP 的情况是 Java 和 HTML 可以组合成一个扩展名为.jsp 的文件。有人说,Servlet 就是在 Java 中写 HTML,而 JSP 就是在 HTML 中写 Java 代码,当然这个说法是很片面且不够准确的。JSP 侧重于视图,Servlet 更侧重于控制逻辑,在 MVC 架构模式中,JSP 适合充当视图(view)而 Servlet 适合充当控制器(controller)。
JSP 是一种 Servlet,但是与 HttpServlet 的工作方式不太一样。HttpServlet 是先由源代码编译为 class 文件后部署到服务器下,为先编译后部署。而 JSP 则是先部署后编译。JSP 会在客户端第一次请求 JSP 文件时被编译为 HttpJspPage 类(接口 Servlet 的一个子类)。该类会被服务器临时存放在服务器工作目录里面。下面通过实例给大家介绍。
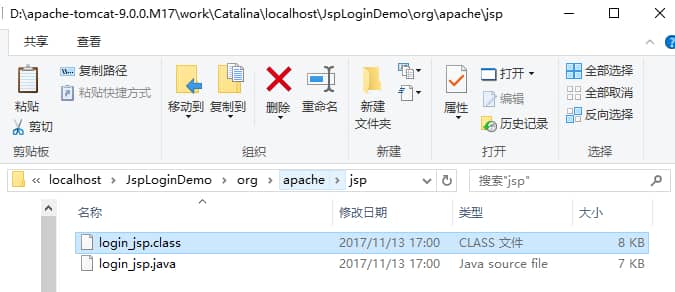
工程 JspLoginDemo 下有一个名为 login.jsp 的 Jsp 文件,把工程第一次部署到服务器上后访问这个 Jsp 文件,我们发现这个目录下多了下图这两个东东。
.class 文件便是 JSP 对应的 Servlet。编译完毕后再运行 class 文件来响应客户端请求。以后客户端访问 login.jsp 的时候,Tomcat 将不再重新编译 JSP 文件,而是直接调用 class 文件来响应客户端请求。
由于 JSP 只会在客户端第一次请求的时候被编译 ,因此第一次请求 JSP 时会感觉比较慢,之后就会感觉快很多。如果把服务器保存的 class 文件删除,服务器也会重新编译 JSP。
开发 Web 程序时经常需要修改 JSP。Tomcat 能够自动检测到 JSP 程序的改动。如果检测到 JSP 源代码发生了改动。Tomcat 会在下次客户端请求 JSP 时重新编译 JSP,而不需要重启 Tomcat。这种自动检测功能是默认开启的,检测改动会消耗少量的时间,在部署 Web 应用的时候可以在 web.xml 中将它关掉。
参考:《javaweb 整合开发王者归来》P97
JSP 有 9 个内置对象:
setAttribute(String name,Object):设置名字为 name 的 request 的参数值getAttribute(String name):返回由 name 指定的属性值getAttributeNames():返回 request 对象所有属性的名字集合,结果是一个枚举的实例getCookies():返回客户端的所有 Cookie 对象,结果是一个 Cookie 数组getCharacterEncoding():返回请求中的字符编码方式 = getContentLength()`:返回请求的 Body 的长度getHeader(String name):获得 HTTP 协议定义的文件头信息getHeaders(String name):返回指定名字的 request Header 的所有值,结果是一个枚举的实例getHeaderNames():返回所以 request Header 的名字,结果是一个枚举的实例getInputStream():返回请求的输入流,用于获得请求中的数据getMethod():获得客户端向服务器端传送数据的方法getParameter(String name):获得客户端传送给服务器端的有 name 指定的参数值getParameterNames():获得客户端传送给服务器端的所有参数的名字,结果是一个枚举的实例getParameterValues(String name):获得有 name 指定的参数的所有值getProtocol():获取客户端向服务器端传送数据所依据的协议名称getQueryString():获得查询字符串getRequestURI():获取发出请求字符串的客户端地址getRemoteAddr():获取客户端的 IP 地址getRemoteHost():获取客户端的名字getSession([Boolean create]):返回和请求相关 SessiongetServerName():获取服务器的名字getServletPath():获取客户端所请求的脚本文件的路径getServerPort():获取服务器的端口号removeAttribute(String name):删除请求中的一个属性从获取方向来看:
getParameter()是获取 POST/GET 传递的参数值;
getAttribute()是获取对象容器中的数据值;
从用途来看:
getParameter()用于客户端重定向时,即点击了链接或提交按扭时传值用,即用于在用表单或 url 重定向传值时接收数据用。
getAttribute() 用于服务器端重定向时,即在 sevlet 中使用了 forward 函数,或 struts 中使用了
mapping.findForward。 getAttribute 只能收到程序用 setAttribute 传过来的值。
另外,可以用 setAttribute(),getAttribute() 发送接收对象.而 getParameter() 显然只能传字符串。setAttribute() 是应用服务器把这个对象放在该页面所对应的一块内存中去,当你的页面服务器重定向到另一个页面时,应用服务器会把这块内存拷贝另一个页面所对应的内存中。这样getAttribute()就能取得你所设下的值,当然这种方法可以传对象。session 也一样,只是对象在内存中的生命周期不一样而已。getParameter()只是应用服务器在分析你送上来的 request 页面的文本时,取得你设在表单或 url 重定向时的值。
总结:
getParameter()返回的是 String,用于读取提交的表单中的值;(获取之后会根据实际需要转换为自己需要的相应类型,比如整型,日期类型啊等等)
getAttribute()返回的是 Object,需进行转换,可用setAttribute()设置成任意对象,使用很灵活,可随时用
include 指令: JSP 可以通过 include 指令来包含其他文件。被包含的文件可以是 JSP 文件、HTML 文件或文本文件。包含的文件就好像是该 JSP 文件的一部分,会被同时编译执行。 语法格式如下:
<%@ include file=”文件相对 url 地址” %>
include 动作: <jsp:include>动作元素用来包含静态和动态的文件。该动作把指定文件插入正在生成的页面。语法格式如下:
<jsp:include page=”相对 URL 地址” flush=”true” />
JSP 中的四种作用域包括 page、request、session 和 application,具体来说:
对于 JSP 页面,可以通过 page 指令进行设置。<%@page isThreadSafe="false"%>
对于 Servlet,可以让自定义的 Servlet 实现 SingleThreadModel 标识接口。
说明:如果将 JSP 或 Servlet 设置成单线程工作模式,会导致每个请求创建一个 Servlet 实例,这种实践将导致严重的性能问题(服务器的内存压力很大,还会导致频繁的垃圾回收),所以通常情况下并不会这么做。
使用 Cookie
向客户端发送 Cookie
1 | Cookie c =new Cookie("name","value"); //创建Cookie |
从客户端读取 Cookie
1 | String name ="name"; |
优点: 数据可以持久保存,不需要服务器资源,简单,基于文本的 Key-Value
缺点: 大小受到限制,用户可以禁用 Cookie 功能,由于保存在本地,有一定的安全风险。
URL 重写
在 URL 中添加用户会话的信息作为请求的参数,或者将唯一的会话 ID 添加到 URL 结尾以标识一个会话。
优点: 在 Cookie 被禁用的时候依然可以使用
缺点: 必须对网站的 URL 进行编码,所有页面必须动态生成,不能用预先记录下来的 URL 进行访问。
隐藏的表单域
1 | <input type="hidden" name="session" value="..." /> |
优点: Cookie 被禁时可以使用
缺点: 所有页面必须是表单提交之后的结果。
HttpSession
在所有会话跟踪技术中,HttpSession 对象是最强大也是功能最多的。当一个用户第一次访问某个网站时会自动创建 HttpSession,每个用户可以访问他自己的 HttpSession。可以通过 HttpServletRequest 对象的 getSession 方 法获得 HttpSession,通过 HttpSession 的 setAttribute 方法可以将一个值放在 HttpSession 中,通过调用 HttpSession 对象的 getAttribute 方法,同时传入属性名就可以获取保存在 HttpSession 中的对象。与上面三种方式不同的 是,HttpSession 放在服务器的内存中,因此不要将过大的对象放在里面,即使目前的 Servlet 容器可以在内存将满时将 HttpSession 中的对象移到其他存储设备中,但是这样势必影响性能。添加到 HttpSession 中的值可以是任意 Java 对象,这个对象最好实现了 Serializable 接口,这样 Servlet 容器在必要的时候可以将其序列化到文件中,否则在序列化时就会出现异常。
Cookie 和 Session 都是用来跟踪浏览器用户身份的会话方式,但是两者的应用场景不太一样。
Cookie 一般用来保存用户信息 比如 ① 我们在 Cookie 中保存已经登录过得用户信息,下次访问网站的时候页面可以自动帮你登录的一些基本信息给填了;② 一般的网站都会有保持登录也就是说下次你再访问网站的时候就不需要重新登录了,这是因为用户登录的时候我们可以存放了一个 Token 在 Cookie 中,下次登录的时候只需要根据 Token 值来查找用户即可(为了安全考虑,重新登录一般要将 Token 重写);③ 登录一次网站后访问网站其他页面不需要重新登录。Session 的主要作用就是通过服务端记录用户的状态。 典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了。
Cookie 数据保存在客户端(浏览器端),Session 数据保存在服务器端。
Cookie 存储在客户端中,而 Session 存储在服务器上,相对来说 Session 安全性更高。如果使用 Cookie 的一些敏感信息不要写入 Cookie 中,最好能将 Cookie 信息加密然后使用到的时候再去服务器端解密。
本文整理完善自下面这两份资料:
数据库(database) - 保存有组织的数据的容器(通常是一个文件或一组文件)。数据表(table) - 某种特定类型数据的结构化清单。模式(schema) - 关于数据库和表的布局及特性的信息。模式定义了数据在表中如何存储,包含存储什么样的数据,数据如何分解,各部分信息如何命名等信息。数据库和表都有模式。列(column) - 表中的一个字段。所有表都是由一个或多个列组成的。行(row) - 表中的一个记录。主键(primary key) - 一列(或一组列),其值能够唯一标识表中每一行。SQL(Structured Query Language),标准 SQL 由 ANSI 标准委员会管理,从而称为 ANSI SQL。各个 DBMS 都有自己的实现,如 PL/SQL、Transact-SQL 等。
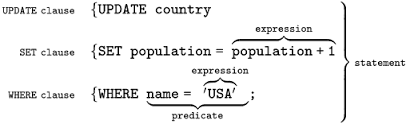
SQL 语法结构包括:
子句 - 是语句和查询的组成成分。(在某些情况下,这些都是可选的。)表达式 - 可以产生任何标量值,或由列和行的数据库表谓词 - 给需要评估的 SQL 三值逻辑(3VL)(true/false/unknown)或布尔真值指定条件,并限制语句和查询的效果,或改变程序流程。查询 - 基于特定条件检索数据。这是 SQL 的一个重要组成部分。语句 - 可以持久地影响纲要和数据,也可以控制数据库事务、程序流程、连接、会话或诊断。SELECT 与 select、Select 是相同的。;)分隔。SQL 语句可以写成一行,也可以分写为多行。
1 | -- 一行 SQL 语句 |
SQL 支持三种注释:
1 | ## 注释1 |
数据定义语言(Data Definition Language,DDL)是 SQL 语言集中负责数据结构定义与数据库对象定义的语言。
DDL 的主要功能是定义数据库对象。
DDL 的核心指令是 CREATE、ALTER、DROP。
数据操纵语言(Data Manipulation Language, DML)是用于数据库操作,对数据库其中的对象和数据运行访问工作的编程语句。
DML 的主要功能是 访问数据,因此其语法都是以读写数据库为主。
DML 的核心指令是 INSERT、UPDATE、DELETE、SELECT。这四个指令合称 CRUD(Create, Read, Update, Delete),即增删改查。
事务控制语言 (Transaction Control Language, TCL) 用于管理数据库中的事务。这些用于管理由 DML 语句所做的更改。它还允许将语句分组为逻辑事务。
TCL 的核心指令是 COMMIT、ROLLBACK。
数据控制语言 (Data Control Language, DCL) 是一种可对数据访问权进行控制的指令,它可以控制特定用户账户对数据表、查看表、预存程序、用户自定义函数等数据库对象的控制权。
DCL 的核心指令是 GRANT、REVOKE。
DCL 以控制用户的访问权限为主,因此其指令作法并不复杂,可利用 DCL 控制的权限有:CONNECT、SELECT、INSERT、UPDATE、DELETE、EXECUTE、USAGE、REFERENCES。
根据不同的 DBMS 以及不同的安全性实体,其支持的权限控制也有所不同。
我们先来介绍 DML 语句用法。 DML 的主要功能是读写数据库实现增删改查。
增删改查,又称为 CRUD,数据库基本操作中的基本操作。
INSERT INTO 语句用于向表中插入新记录。
插入完整的行
1 | # 插入一行 |
插入行的一部分
1 | INSERT INTO user(username, password, email) |
插入查询出来的数据
1 | INSERT INTO user(username) |
UPDATE 语句用于更新表中的记录。
1 | UPDATE user |
DELETE 语句用于删除表中的记录。TRUNCATE TABLE 可以清空表,也就是删除所有行。说明:TRUNCATE 语句不属于 DML 语法而是 DDL 语法。删除表中的指定数据
1 | DELETE FROM user |
清空表中的数据
1 | TRUNCATE TABLE user; |
SELECT 语句用于从数据库中查询数据。
DISTINCT 用于返回唯一不同的值。它作用于所有列,也就是说所有列的值都相同才算相同。
LIMIT 限制返回的行数。可以有两个参数,第一个参数为起始行,从 0 开始;第二个参数为返回的总行数。
ASC:升序(默认)DESC:降序查询单列
1 | SELECT prod_name |
查询多列
1 | SELECT prod_id, prod_name, prod_price |
查询所有列
1 | SELECT * |
查询不同的值
1 | SELECT DISTINCT |
限制查询结果
1 | -- 返回前 5 行 |
order by 用于对结果集按照一个列或者多个列进行排序。默认按照升序对记录进行排序,如果需要按照降序对记录进行排序,可以使用 desc 关键字。
order by 对多列排序的时候,先排序的列放前面,后排序的列放后面。并且,不同的列可以有不同的排序规则。
1 | SELECT * FROM products |
**group by**:
group by 子句将记录分组到汇总行中。group by 为每个组返回一个记录。group by 通常还涉及聚合count,max,sum,avg 等。group by 可以按一列或多列进行分组。group by 按分组字段进行排序后,order by 可以以汇总字段来进行排序。分组
1 | SELECT cust_name, COUNT(cust_address) AS addr_num |
分组后排序
1 | SELECT cust_name, COUNT(cust_address) AS addr_num |
**having**:
having 用于对汇总的 group by 结果进行过滤。having 一般都是和 group by 连用。where 和 having 可以在相同的查询中。使用 WHERE 和 HAVING 过滤数据
1 | SELECT cust_name, COUNT(*) AS NumberOfOrders |
**having vs where**:
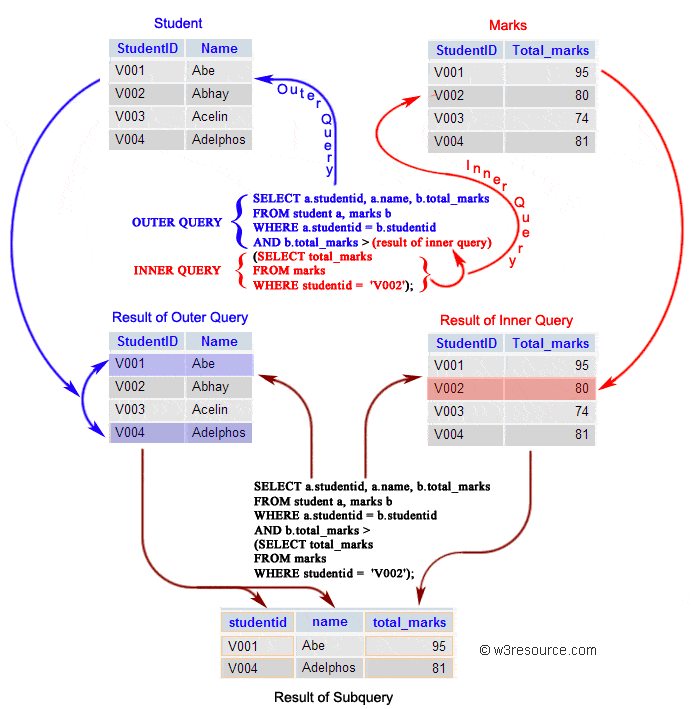
where:过滤过滤指定的行,后面不能加聚合函数(分组函数)。where 在group by 前。having:过滤分组,一般都是和 group by 连用,不能单独使用。having 在 group by 之后。子查询是嵌套在较大查询中的 SQL 查询,也称内部查询或内部选择,包含子查询的语句也称为外部查询或外部选择。简单来说,子查询就是指将一个 select 查询(子查询)的结果作为另一个 SQL 语句(主查询)的数据来源或者判断条件。
子查询可以嵌入 SELECT、INSERT、UPDATE 和 DELETE 语句中,也可以和 =、<、>、IN、BETWEEN、EXISTS 等运算符一起使用。
子查询常用在 WHERE 子句和 FROM 子句后边:
WHERE 子句时,根据不同的运算符,子查询可以返回单行单列、多行单列、单行多列数据。子查询就是要返回能够作为 WHERE 子句查询条件的值。FROM 子句时,一般返回多行多列数据,相当于返回一张临时表,这样才符合 FROM 后面是表的规则。这种做法能够实现多表联合查询。注意:MYSQL 数据库从 4.1 版本才开始支持子查询,早期版本是不支持的。
用于 WHERE 子句的子查询的基本语法如下:
1 | select column_name [, column_name ] |
( )内。operator 表示用于 where 子句的运算符。用于 FROM 子句的子查询的基本语法如下:
1 | select column_name [, column_name ] |
用于 FROM 的子查询返回的结果相当于一张临时表,所以需要使用 AS 关键字为该临时表起一个名字。
子查询的子查询
1 | SELECT cust_name, cust_contact |
内部查询首先在其父查询之前执行,以便可以将内部查询的结果传递给外部查询。执行过程可以参考下图:
WHERE 子句用于过滤记录,即缩小访问数据的范围。WHERE 后跟一个返回 true 或 false 的条件。WHERE 可以与 SELECT,UPDATE 和 DELETE 一起使用。WHERE 子句中使用的操作符。| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 != |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN | 在某个范围内 |
| LIKE | 搜索某种模式 |
| IN | 指定针对某个列的多个可能值 |
SELECT 语句中的 WHERE 子句
1 | SELECT * FROM Customers |
UPDATE 语句中的 WHERE 子句
1 | UPDATE Customers |
DELETE 语句中的 WHERE 子句
1 | DELETE FROM Customers |
IN 操作符在 WHERE 子句中使用,作用是在指定的几个特定值中任选一个值。BETWEEN 操作符在 WHERE 子句中使用,作用是选取介于某个范围内的值。IN 示例
1 | SELECT * |
BETWEEN 示例
1 | SELECT * |
AND、OR、NOT 是用于对过滤条件的逻辑处理指令。AND 优先级高于 OR,为了明确处理顺序,可以使用 ()。AND 操作符表示左右条件都要满足。OR 操作符表示左右条件满足任意一个即可。NOT 操作符用于否定一个条件。AND 示例
1 | SELECT prod_id, prod_name, prod_price |
OR 示例
1 | SELECT prod_id, prod_name, prod_price |
NOT 示例
1 | SELECT * |
LIKE 操作符在 WHERE 子句中使用,作用是确定字符串是否匹配模式。LIKE。LIKE 支持两个通配符匹配选项:% 和 _。% 表示任何字符出现任意次数。_ 表示任何字符出现一次。% 示例
1 | SELECT prod_id, prod_name, prod_price |
_ 示例
1 | SELECT prod_id, prod_name, prod_price |
JOIN 是“连接”的意思,顾名思义,SQL JOIN 子句用于将两个或者多个表联合起来进行查询。
连接表时需要在每个表中选择一个字段,并对这些字段的值进行比较,值相同的两条记录将合并为一条。连接表的本质就是将不同表的记录合并起来,形成一张新表。当然,这张新表只是临时的,它仅存在于本次查询期间。
使用 JOIN 连接两个表的基本语法如下:
1 | select table1.column1, table2.column2... |
table1.common_column1 = table2.common_column2 是连接条件,只有满足此条件的记录才会合并为一行。您可以使用多个运算符来连接表,例如 =、>、<、<>、<=、>=、!=、between、like 或者 not,但是最常见的是使用 =。
当两个表中有同名的字段时,为了帮助数据库引擎区分是哪个表的字段,在书写同名字段名时需要加上表名。当然,如果书写的字段名在两个表中是唯一的,也可以不使用以上格式,只写字段名即可。
另外,如果两张表的关联字段名相同,也可以使用 USING子句来代替 ON,举个例子:
1 | # join....on |
ON 和 WHERE 的区别:
ON 就是连接条件,它决定临时表的生成。WHERE 是在临时表生成以后,再对临时表中的数据进行过滤,生成最终的结果集,这个时候已经没有 JOIN-ON 了。所以总结来说就是:SQL 先根据 ON 生成一张临时表,然后再根据 WHERE 对临时表进行筛选。
SQL 允许在 JOIN 左边加上一些修饰性的关键词,从而形成不同类型的连接,如下表所示:
| 连接类型 | 说明 |
|---|---|
| INNER JOIN 内连接 | (默认连接方式)只有当两个表都存在满足条件的记录时才会返回行。 |
| LEFT JOIN / LEFT OUTER JOIN 左(外)连接 | 返回左表中的所有行,即使右表中没有满足条件的行也是如此。 |
| RIGHT JOIN / RIGHT OUTER JOIN 右(外)连接 | 返回右表中的所有行,即使左表中没有满足条件的行也是如此。 |
| FULL JOIN / FULL OUTER JOIN 全(外)连接 | 只要其中有一个表存在满足条件的记录,就返回行。 |
| SELF JOIN | 将一个表连接到自身,就像该表是两个表一样。为了区分两个表,在 SQL 语句中需要至少重命名一个表。 |
| CROSS JOIN | 交叉连接,从两个或者多个连接表中返回记录集的笛卡尔积。 |
下图展示了 LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN 相关的 7 种用法。
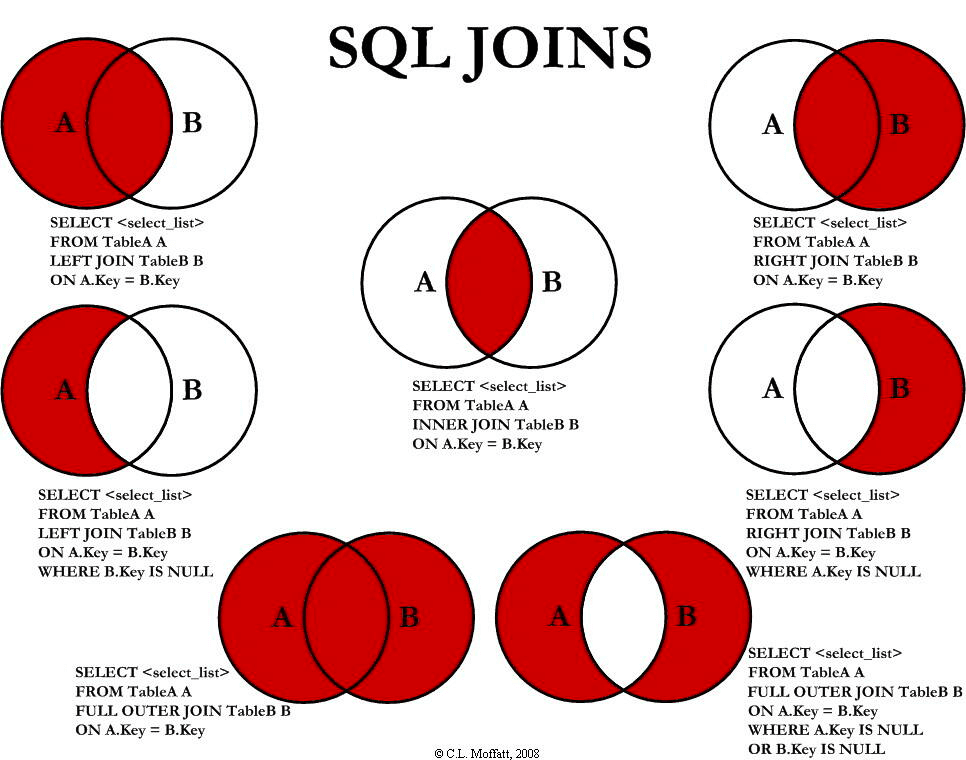
如果不加任何修饰词,只写 JOIN,那么默认为 INNER JOIN
对于 INNER JOIN 来说,还有一种隐式的写法,称为 “隐式内连接”,也就是没有 INNER JOIN 关键字,使用 WHERE 语句实现内连接的功能
1 | # 隐式内连接 |
UNION 运算符将两个或更多查询的结果组合起来,并生成一个结果集,其中包含来自 UNION 中参与查询的提取行。
UNION 基本规则:
默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
1 | SELECT column_name(s) FROM table1 |
UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
JOIN vs UNION:
JOIN 中连接表的列可能不同,但在 UNION 中,所有查询的列数和列顺序必须相同。UNION 将查询之后的行放在一起(垂直放置),但 JOIN 将查询之后的列放在一起(水平放置),即它构成一个笛卡尔积。不同数据库的函数往往各不相同,因此不可移植。本节主要以 MySQL 的函数为例。
| 函数 | 说明 |
|---|---|
LEFT()、RIGHT() |
左边或者右边的字符 |
LOWER()、UPPER() |
转换为小写或者大写 |
LTRIM()、RTRIM() |
去除左边或者右边的空格 |
LENGTH() |
长度,以字节为单位 |
SOUNDEX() |
转换为语音值 |
其中, SOUNDEX() 可以将一个字符串转换为描述其语音表示的字母数字模式。
1 | SELECT * |
YYYY-MM-DDHH:MM:SS| 函 数 | 说 明 |
|---|---|
AddDate() |
增加一个日期(天、周等) |
AddTime() |
增加一个时间(时、分等) |
CurDate() |
返回当前日期 |
CurTime() |
返回当前时间 |
Date() |
返回日期时间的日期部分 |
DateDiff() |
计算两个日期之差 |
Date_Add() |
高度灵活的日期运算函数 |
Date_Format() |
返回一个格式化的日期或时间串 |
Day() |
返回一个日期的天数部分 |
DayOfWeek() |
对于一个日期,返回对应的星期几 |
Hour() |
返回一个时间的小时部分 |
Minute() |
返回一个时间的分钟部分 |
Month() |
返回一个日期的月份部分 |
Now() |
返回当前日期和时间 |
Second() |
返回一个时间的秒部分 |
Time() |
返回一个日期时间的时间部分 |
Year() |
返回一个日期的年份部分 |
| 函数 | 说明 |
|---|---|
| SIN() | 正弦 |
| COS() | 余弦 |
| TAN() | 正切 |
| ABS() | 绝对值 |
| SQRT() | 平方根 |
| MOD() | 余数 |
| EXP() | 指数 |
| PI() | 圆周率 |
| RAND() | 随机数 |
| 函 数 | 说 明 |
|---|---|
AVG() |
返回某列的平均值 |
COUNT() |
返回某列的行数 |
MAX() |
返回某列的最大值 |
MIN() |
返回某列的最小值 |
SUM() |
返回某列值之和 |
AVG() 会忽略 NULL 行。
使用 DISTINCT 可以让汇总函数值汇总不同的值。
1 | SELECT AVG(DISTINCT col1) AS avg_col |
接下来,我们来介绍 DDL 语句用法。DDL 的主要功能是定义数据库对象(如:数据库、数据表、视图、索引等)
1 | CREATE DATABASE test; |
1 | DROP DATABASE test; |
1 | USE test; |
普通创建
1 | CREATE TABLE user ( |
根据已有的表创建新表
1 | CREATE TABLE vip_user AS |
1 | DROP TABLE user; |
添加列
1 | ALTER TABLE user |
删除列
1 | ALTER TABLE user |
修改列
1 | ALTER TABLE `user` |
添加主键
1 | ALTER TABLE user |
删除主键
1 | ALTER TABLE user |
定义:
作用:
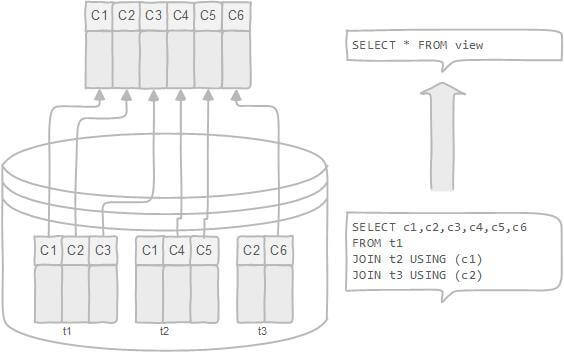
1 | CREATE VIEW top_10_user_view AS |
1 | DROP VIEW top_10_user_view; |
索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。
索引的作用就相当于书的目录。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
优点:
缺点:
但是,使用索引一定能提高查询性能吗?
大多数情况下,索引查询都是比全表扫描要快的。但是如果数据库的数据量不大,那么使用索引也不一定能够带来很大提升。
关于索引的详细介绍,请看我写的 MySQL 索引详解 这篇文章。
1 | CREATE INDEX user_index |
1 | ALTER table user ADD INDEX user_index(id) |
1 | CREATE UNIQUE INDEX user_index |
1 | ALTER TABLE user |
SQL 约束用于规定表中的数据规则。
如果存在违反约束的数据行为,行为会被约束终止。
约束可以在创建表时规定(通过 CREATE TABLE 语句),或者在表创建之后规定(通过 ALTER TABLE 语句)。
约束类型:
NOT NULL - 指示某列不能存储 NULL 值。UNIQUE - 保证某列的每行必须有唯一的值。PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。CHECK - 保证列中的值符合指定的条件。DEFAULT - 规定没有给列赋值时的默认值。创建表时使用约束条件:
1 | CREATE TABLE Users ( |
接下来,我们来介绍 TCL 语句用法。TCL 的主要功能是管理数据库中的事务。
不能回退 SELECT 语句,回退 SELECT 语句也没意义;也不能回退 CREATE 和 DROP 语句。
MySQL 默认是隐式提交,每执行一条语句就把这条语句当成一个事务然后进行提交。当出现 START TRANSACTION 语句时,会关闭隐式提交;当 COMMIT 或 ROLLBACK 语句执行后,事务会自动关闭,重新恢复隐式提交。
通过 set autocommit=0 可以取消自动提交,直到 set autocommit=1 才会提交;autocommit 标记是针对每个连接而不是针对服务器的。
指令:
START TRANSACTION - 指令用于标记事务的起始点。SAVEPOINT - 指令用于创建保留点。ROLLBACK TO - 指令用于回滚到指定的保留点;如果没有设置保留点,则回退到 START TRANSACTION 语句处。COMMIT - 提交事务。1 | -- 开始事务 |
接下来,我们来介绍 DCL 语句用法。DCL 的主要功能是控制用户的访问权限。
要授予用户帐户权限,可以用GRANT命令。要撤销用户的权限,可以用REVOKE命令。这里以 MySQL 为例,介绍权限控制实际应用。
GRANT授予权限语法:
1 | GRANT privilege,[privilege],.. ON privilege_level |
简单解释一下:
GRANT关键字后指定一个或多个权限。如果授予用户多个权限,则每个权限由逗号分隔。ON privilege_level 确定权限应用级别。MySQL 支持 global(*.*),database(database.*),table(database.table)和列级别。如果使用列权限级别,则必须在每个权限之后指定一个或逗号分隔列的列表。user 是要授予权限的用户。如果用户已存在,则GRANT语句将修改其权限。否则,GRANT语句将创建一个新用户。可选子句IDENTIFIED BY允许您为用户设置新的密码。REQUIRE tsl_option指定用户是否必须通过 SSL,X059 等安全连接连接到数据库服务器。WITH GRANT OPTION 子句允许您授予其他用户或从其他用户中删除您拥有的权限。此外,您可以使用WITH子句分配 MySQL 数据库服务器的资源,例如,设置用户每小时可以使用的连接数或语句数。这在 MySQL 共享托管等共享环境中非常有用。REVOKE 撤销权限语法:
1 | REVOKE privilege_type [(column_list)] |
简单解释一下:
REVOKE 关键字后面指定要从用户撤消的权限列表。您需要用逗号分隔权限。ON 子句中撤销特权的特权级别。FROM 子句中的权限的用户帐户。GRANT 和 REVOKE 可在几个层次上控制访问权限:
GRANT ALL 和 REVOKE ALL;ON database.*;ON database.table;新创建的账户没有任何权限。账户用 username@host 的形式定义,username@% 使用的是默认主机名。MySQL 的账户信息保存在 mysql 这个数据库中。
1 | USE mysql; |
下表说明了可用于GRANT和REVOKE语句的所有允许权限:
| 特权 | 说明 | 级别 | |||||
|---|---|---|---|---|---|---|---|
| 全局 | 数据库 | 表 | 列 | 程序 | 代理 | ||
| ALL [PRIVILEGES] | 授予除 GRANT OPTION 之外的指定访问级别的所有权限 | ||||||
| ALTER | 允许用户使用 ALTER TABLE 语句 | X | X | X | |||
| ALTER ROUTINE | 允许用户更改或删除存储的例程 | X | X | X | |||
| CREATE | 允许用户创建数据库和表 | X | X | X | |||
| CREATE ROUTINE | 允许用户创建存储的例程 | X | X | ||||
| CREATE TABLESPACE | 允许用户创建,更改或删除表空间和日志文件组 | X | |||||
| CREATE TEMPORARY TABLES | 允许用户使用 CREATE TEMPORARY TABLE 创建临时表 | X | X | ||||
| CREATE USER | 允许用户使用 CREATE USER,DROP USER,RENAME USER 和 REVOKE ALL PRIVILEGES 语句。 | X | |||||
| CREATE VIEW | 允许用户创建或修改视图。 | X | X | X | |||
| DELETE | 允许用户使用 DELETE | X | X | X | |||
| DROP | 允许用户删除数据库,表和视图 | X | X | X | |||
| EVENT | 启用事件计划程序的事件使用。 | X | X | ||||
| EXECUTE | 允许用户执行存储的例程 | X | X | X | |||
| FILE | 允许用户读取数据库目录中的任何文件。 | X | |||||
| GRANT OPTION | 允许用户拥有授予或撤消其他帐户权限的权限。 | X | X | X | X | X | |
| INDEX | 允许用户创建或删除索引。 | X | X | X | |||
| INSERT | 允许用户使用 INSERT 语句 | X | X | X | X | ||
| LOCK TABLES | 允许用户对具有 SELECT 权限的表使用 LOCK TABLES | X | X | ||||
| PROCESS | 允许用户使用 SHOW PROCESSLIST 语句查看所有进程。 | X | |||||
| PROXY | 启用用户代理。 | ||||||
| REFERENCES | 允许用户创建外键 | X | X | X | X | ||
| RELOAD | 允许用户使用 FLUSH 操作 | X | |||||
| REPLICATION CLIENT | 允许用户查询以查看主服务器或从属服务器的位置 | X | |||||
| REPLICATION SLAVE | 允许用户使用复制从属从主服务器读取二进制日志事件。 | X | |||||
| SELECT | 允许用户使用 SELECT 语句 | X | X | X | X | ||
| SHOW DATABASES | 允许用户显示所有数据库 | X | |||||
| SHOW VIEW | 允许用户使用 SHOW CREATE VIEW 语句 | X | X | X | |||
| SHUTDOWN | 允许用户使用 mysqladmin shutdown 命令 | X | |||||
| SUPER | 允许用户使用其他管理操作,例如 CHANGE MASTER TO,KILL,PURGE BINARY LOGS,SET GLOBAL 和 mysqladmin 命令 | X | |||||
| TRIGGER | 允许用户使用 TRIGGER 操作。 | X | X | X | |||
| UPDATE | 允许用户使用 UPDATE 语句 | X | X | X | X | ||
| USAGE | 相当于“没有特权” |
1 | CREATE USER myuser IDENTIFIED BY 'mypassword'; |
1 | UPDATE user SET user='newuser' WHERE user='myuser'; |
1 | DROP USER myuser; |
1 | SHOW GRANTS FOR myuser; |
1 | GRANT SELECT, INSERT ON *.* TO myuser; |
1 | REVOKE SELECT, INSERT ON *.* FROM myuser; |
1 | SET PASSWORD FOR myuser = 'mypass'; |
存储过程可以看成是对一系列 SQL 操作的批处理。存储过程可以由触发器,其他存储过程以及 Java, Python,PHP 等应用程序调用。
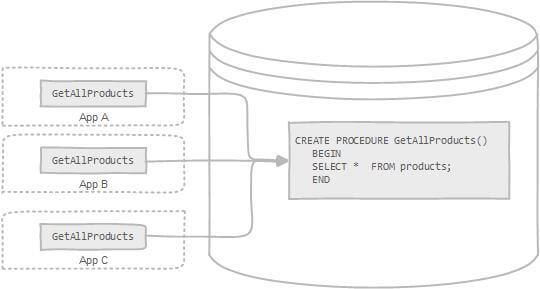
使用存储过程的好处:
创建存储过程:
; 为结束符,而存储过程中也包含了分号,因此会错误把这部分分号当成是结束符,造成语法错误。in、out 和 inout 三种参数。select into 语句。需要注意的是:阿里巴巴《Java 开发手册》强制禁止使用存储过程。因为存储过程难以调试和扩展,更没有移植性。

至于到底要不要在项目中使用,还是要看项目实际需求,权衡好利弊即可!
1 | DROP PROCEDURE IF EXISTS `proc_adder`; |
1 | set @b=5; |
游标(cursor)是一个存储在 DBMS 服务器上的数据库查询,它不是一条 SELECT 语句,而是被该语句检索出来的结果集。
在存储过程中使用游标可以对一个结果集进行移动遍历。
游标主要用于交互式应用,其中用户需要滚动屏幕上的数据,并对数据进行浏览或做出更改。
使用游标的几个明确步骤:
在使用游标前,必须声明(定义)它。这个过程实际上没有检索数据, 它只是定义要使用的 SELECT 语句和游标选项。
一旦声明,就必须打开游标以供使用。这个过程用前面定义的 SELECT 语句把数据实际检索出来。
对于填有数据的游标,根据需要取出(检索)各行。
在结束游标使用时,必须关闭游标,可能的话,释放游标(有赖于具
体的 DBMS)。
1 | DELIMITER $ |
触发器是一种与表操作有关的数据库对象,当触发器所在表上出现指定事件时,将调用该对象,即表的操作事件触发表上的触发器的执行。
我们可以使用触发器来进行审计跟踪,把修改记录到另外一张表中。
使用触发器的优点:
使用触发器的缺点:
MySQL 不允许在触发器中使用 CALL 语句 ,也就是不能调用存储过程。
注意:在 MySQL 中,分号
;是语句结束的标识符,遇到分号表示该段语句已经结束,MySQL 可以开始执行了。因此,解释器遇到触发器执行动作中的分号后就开始执行,然后会报错,因为没有找到和 BEGIN 匹配的 END。这时就会用到
DELIMITER命令(DELIMITER 是定界符,分隔符的意思)。它是一条命令,不需要语句结束标识,语法为:DELIMITER new_delimiter。new_delimiter可以设为 1 个或多个长度的符号,默认的是分号;,我们可以把它修改为其他符号,如$-DELIMITER $。在这之后的语句,以分号结束,解释器不会有什么反应,只有遇到了$,才认为是语句结束。注意,使用完之后,我们还应该记得把它给修改回来。
在 MySQL 5.7.2 版之前,可以为每个表定义最多六个触发器。
BEFORE INSERT - 在将数据插入表格之前激活。AFTER INSERT - 将数据插入表格后激活。BEFORE UPDATE - 在更新表中的数据之前激活。AFTER UPDATE - 更新表中的数据后激活。BEFORE DELETE - 在从表中删除数据之前激活。AFTER DELETE - 从表中删除数据后激活。但是,从 MySQL 版本 5.7.2+开始,可以为同一触发事件和操作时间定义多个触发器。
**NEW 和 OLD**:
NEW 和 OLD 关键字,用来表示触发器的所在表中,触发了触发器的那一行数据。INSERT 型触发器中,NEW 用来表示将要(BEFORE)或已经(AFTER)插入的新数据;UPDATE 型触发器中,OLD 用来表示将要或已经被修改的原数据,NEW 用来表示将要或已经修改为的新数据;DELETE 型触发器中,OLD 用来表示将要或已经被删除的原数据;NEW.columnName (columnName 为相应数据表某一列名)提示:为了理解触发器的要点,有必要先了解一下创建触发器的指令。
CREATE TRIGGER 指令用于创建触发器。
语法:
1 | CREATE TRIGGER trigger_name |
说明:
trigger_name:触发器名trigger_time : 触发器的触发时机。取值为 BEFORE 或 AFTER。trigger_event : 触发器的监听事件。取值为 INSERT、UPDATE 或 DELETE。table_name : 触发器的监听目标。指定在哪张表上建立触发器。FOR EACH ROW: 行级监视,Mysql 固定写法,其他 DBMS 不同。trigger_statements: 触发器执行动作。是一条或多条 SQL 语句的列表,列表内的每条语句都必须用分号 ; 来结尾。当触发器的触发条件满足时,将会执行 BEGIN 和 END 之间的触发器执行动作。
示例:
1 | DELIMITER $ |
1 | SHOW TRIGGERS; |
1 | DROP TRIGGER IF EXISTS trigger_insert_user; |