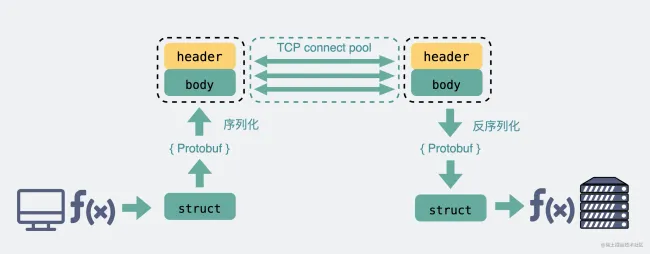
开发岗中总是会考很多计算机网络的知识点,但如果让面试官只考一道题,便涵盖最多的计网知识点,那可能就是 网页浏览的全过程 了。本篇文章将带大家从头到尾过一遍这道被考烂的面试题,必会!!!
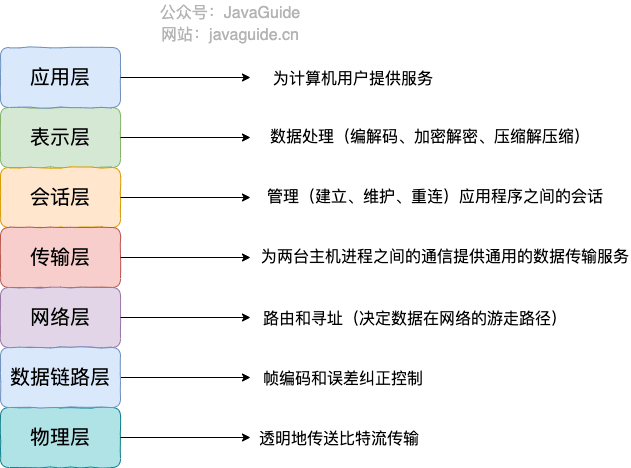
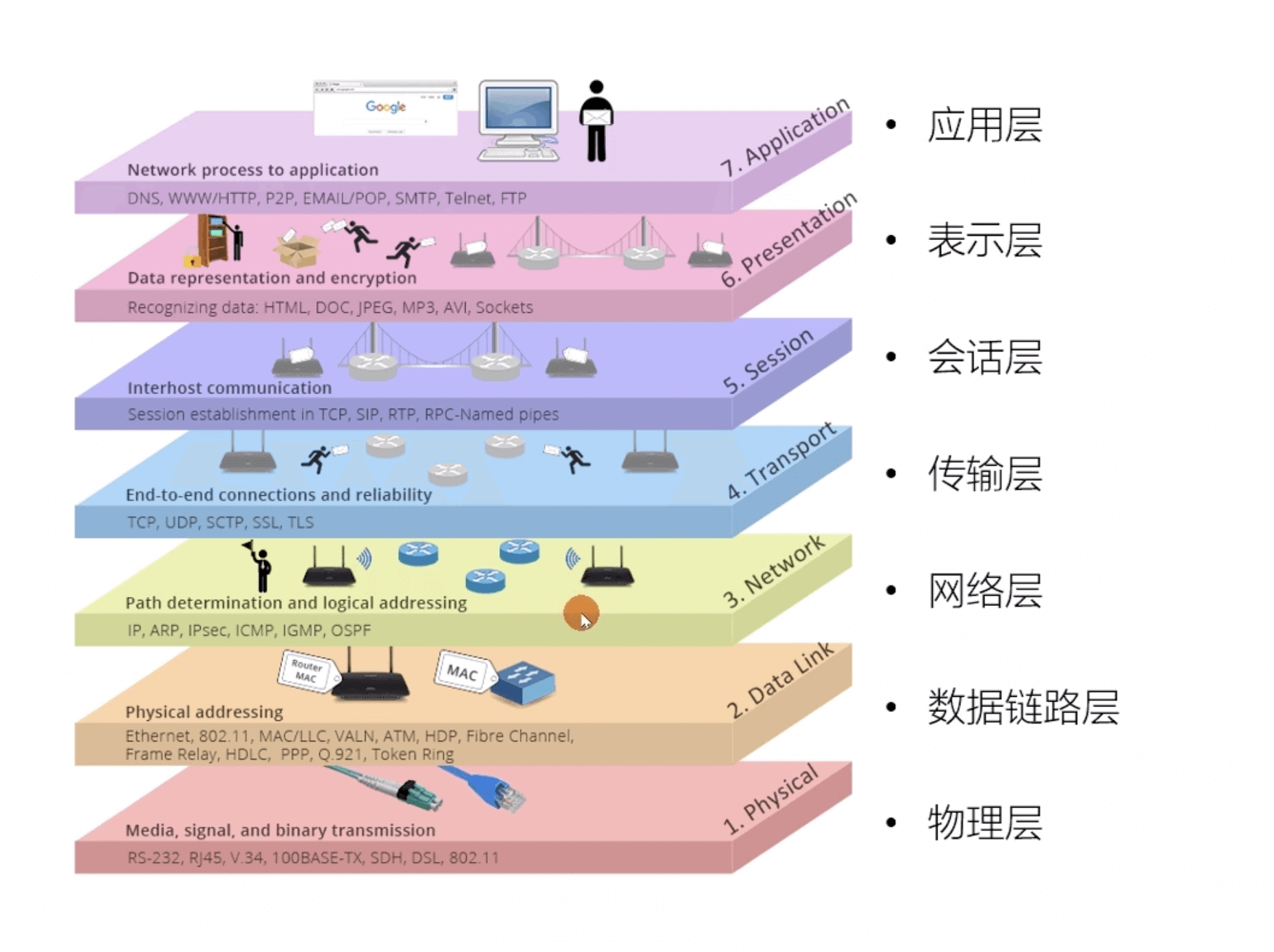
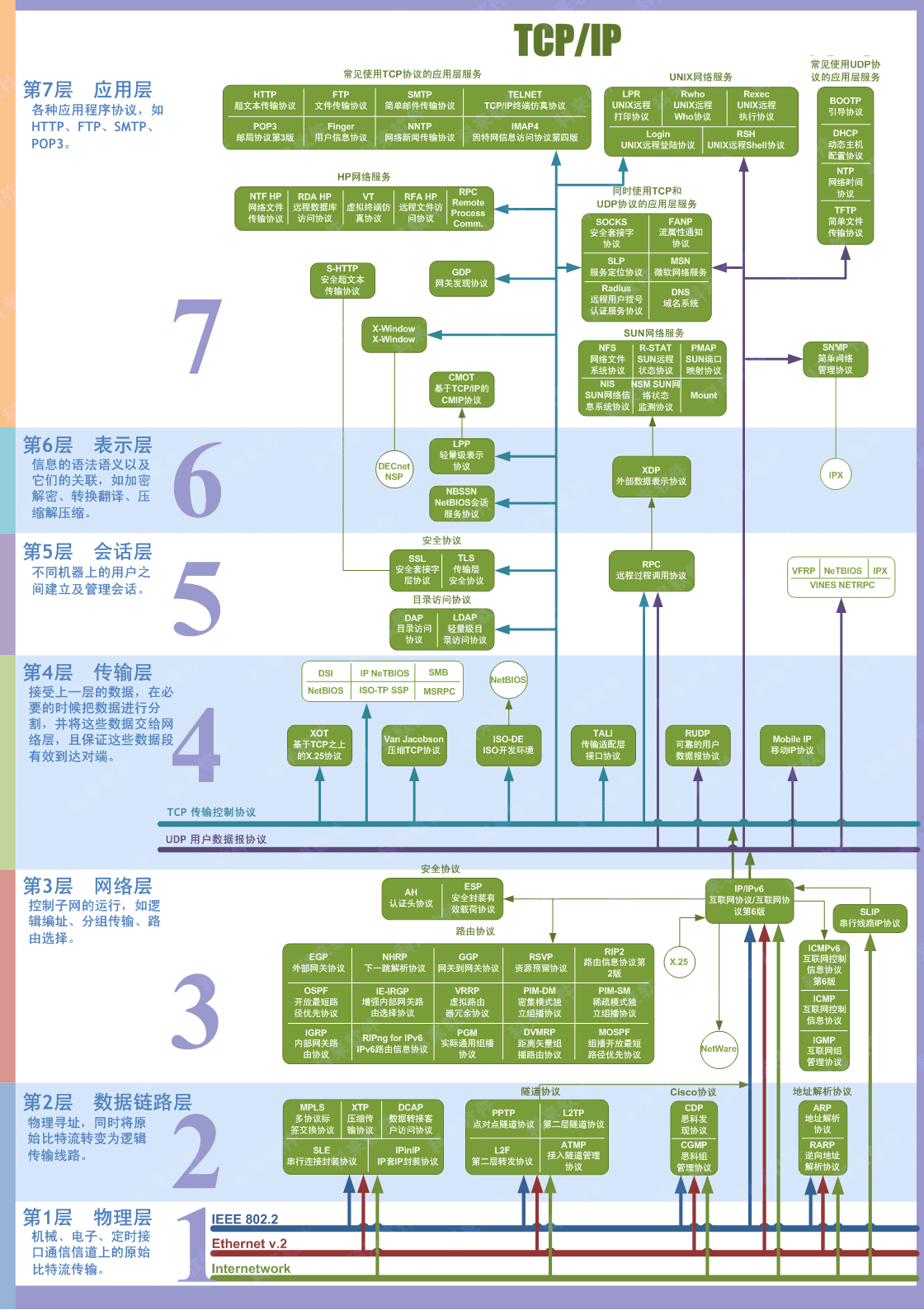
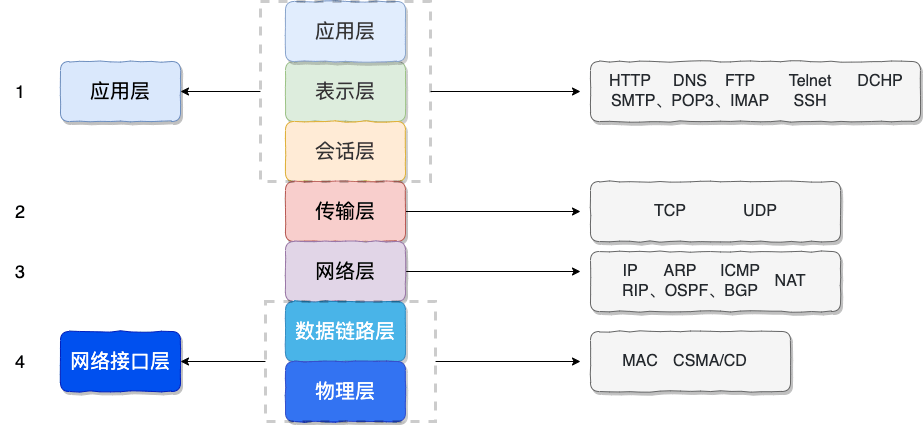
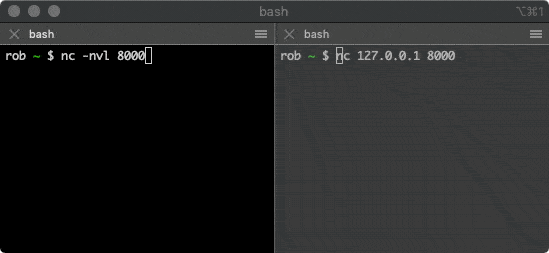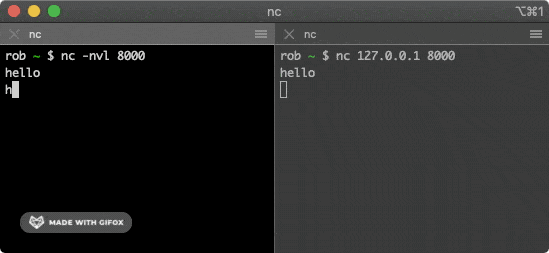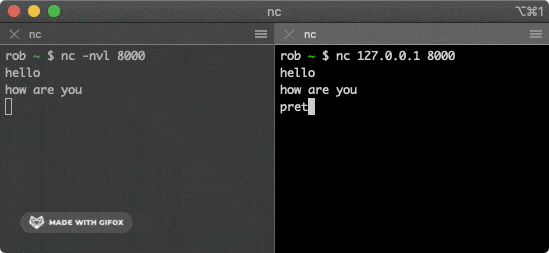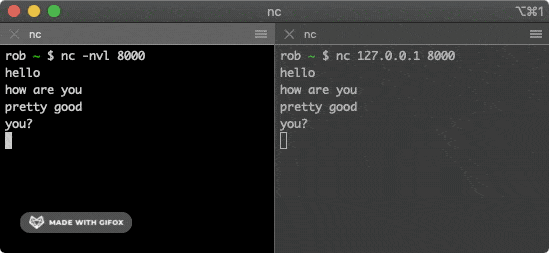
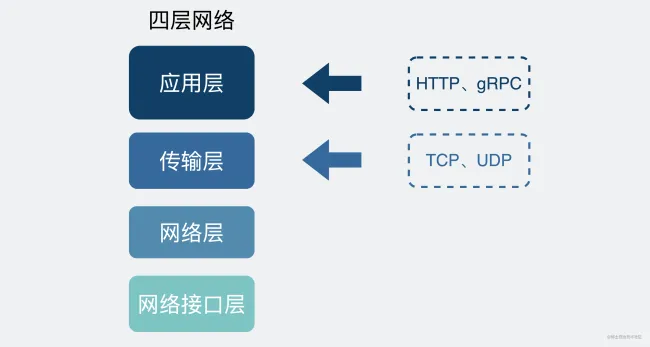
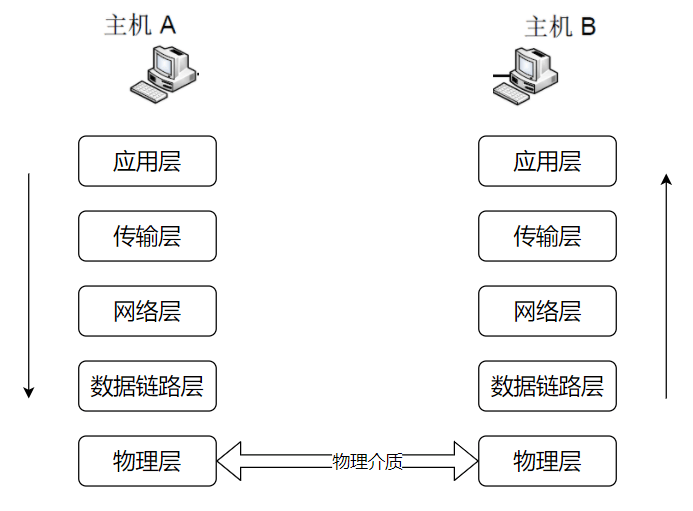
总的来说,网络通信模型可以用下图来表示,也就是大家只要熟记网络结构五层模型,按照这个体系,很多知识点都能顺出来了。访问网页的过程也是如此。
开始之前,我们先简单过一遍完整流程:
- 在浏览器中输入指定网页的 URL。
- 浏览器通过 DNS 协议,获取域名对应的 IP 地址。
- 浏览器根据 IP 地址和端口号,向目标服务器发起一个 TCP 连接请求。
- 浏览器在 TCP 连接上,向服务器发送一个 HTTP 请求报文,请求获取网页的内容。
- 服务器收到 HTTP 请求报文后,处理请求,并返回 HTTP 响应报文给浏览器。
- 浏览器收到 HTTP 响应报文后,解析响应体中的 HTML 代码,渲染网页的结构和样式,同时根据 HTML 中的其他资源的 URL(如图片、CSS、JS 等),再次发起 HTTP 请求,获取这些资源的内容,直到网页完全加载显示。
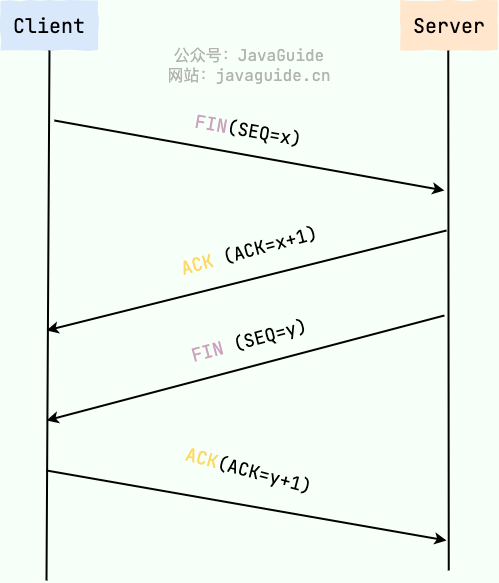
- 浏览器在不需要和服务器通信时,可以主动关闭 TCP 连接,或者等待服务器的关闭请求。
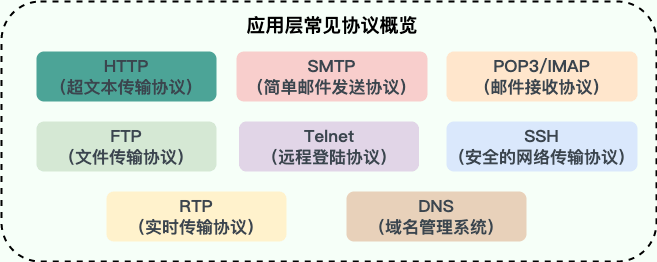
应用层
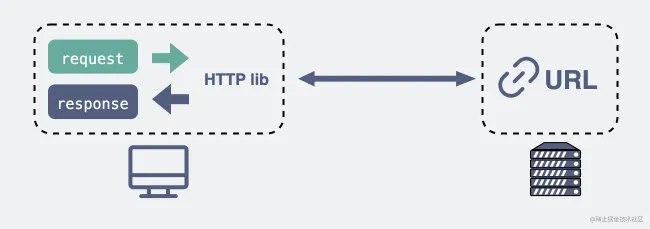
一切的开始——打开浏览器,在地址栏输入 URL,回车确认。那么,什么是 URL?访问 URL 有什么用?
URL
URL(Uniform Resource Locators),即统一资源定位器。网络上的所有资源都靠 URL 来定位,每一个文件就对应着一个 URL,就像是路径地址。理论上,文件资源和 URL 一一对应。实际上也有例外,比如某些 URL 指向的文件已经被重定位到另一个位置,这样就有多个 URL 指向同一个文件。
URL 的组成结构

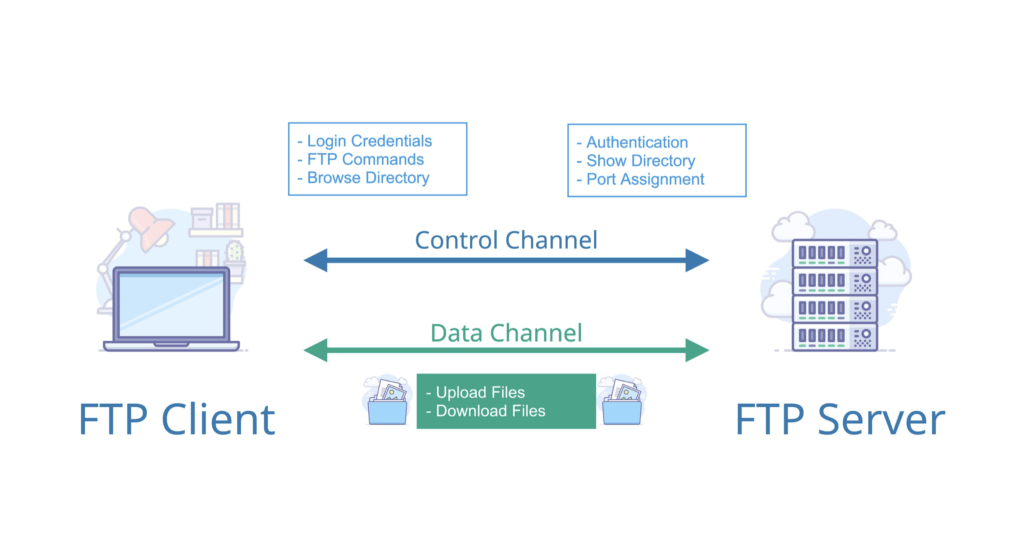
- 协议。URL 的前缀通常表示了该网址采用了何种应用层协议,通常有两种——HTTP 和 HTTPS。当然也有一些不太常见的前缀头,比如文件传输时用到的
ftp:。 - 域名。域名便是访问网址的通用名,这里也有可能是网址的 IP 地址,域名可以理解为 IP 地址的可读版本,毕竟绝大部分人都不会选择记住一个网址的 IP 地址。
- 端口。如果指明了访问网址的端口的话,端口会紧跟在域名后面,并用一个冒号隔开。
- 资源路径。域名(端口)后紧跟的就是资源路径,从第一个
/开始,表示从服务器上根目录开始进行索引到的文件路径,上图中要访问的文件就是服务器根目录下/path/to/myfile.html。早先的设计是该文件通常物理存储于服务器主机上,但现在随着网络技术的进步,该文件不一定会物理存储在服务器主机上,有可能存放在云上,而文件路径也有可能是虚拟的(遵循某种规则)。 - 参数。参数是浏览器在向服务器提交请求时,在 URL 中附带的参数。服务器解析请求时,会提取这些参数。参数采用键值对的形式
key=value,每一个键值对使用&隔开。参数的具体含义和请求操作的具体方法有关。 - 锚点。锚点顾名思义,是在要访问的页面上的一个锚。要访问的页面大部分都多于一页,如果指定了锚点,那么在客户端显示该网页是就会定位到锚点处,相当于一个小书签。值得一提的是,在 URL 中,锚点以
#开头,并且不会作为请求的一部分发送给服务端。
DNS
键入了 URL 之后,第一个重头戏登场——DNS 服务器解析。DNS(Domain Name System)域名系统,要解决的是 域名和 IP 地址的映射问题 。毕竟,域名只是一个网址便于记住的名字,而网址真正存在的地址其实是 IP 地址。
传送门:DNS 域名系统详解(应用层)
HTTP/HTTPS
利用 DNS 拿到了目标主机的 IP 地址之后,浏览器便可以向目标 IP 地址发送 HTTP 报文,请求需要的资源了。在这里,根据目标网站的不同,请求报文可能是 HTTP 协议或安全性增强的 HTTPS 协议。
传送门:
传输层
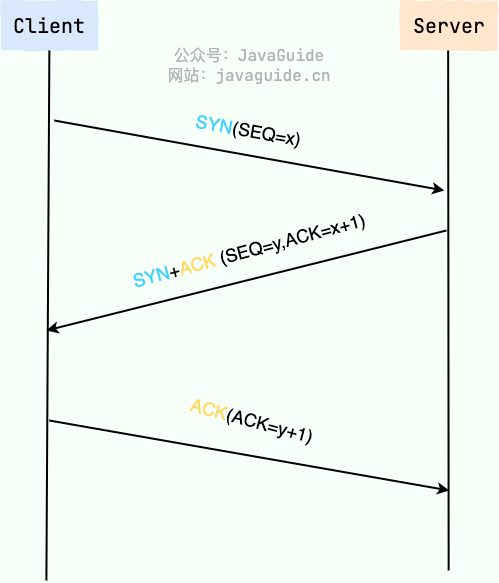
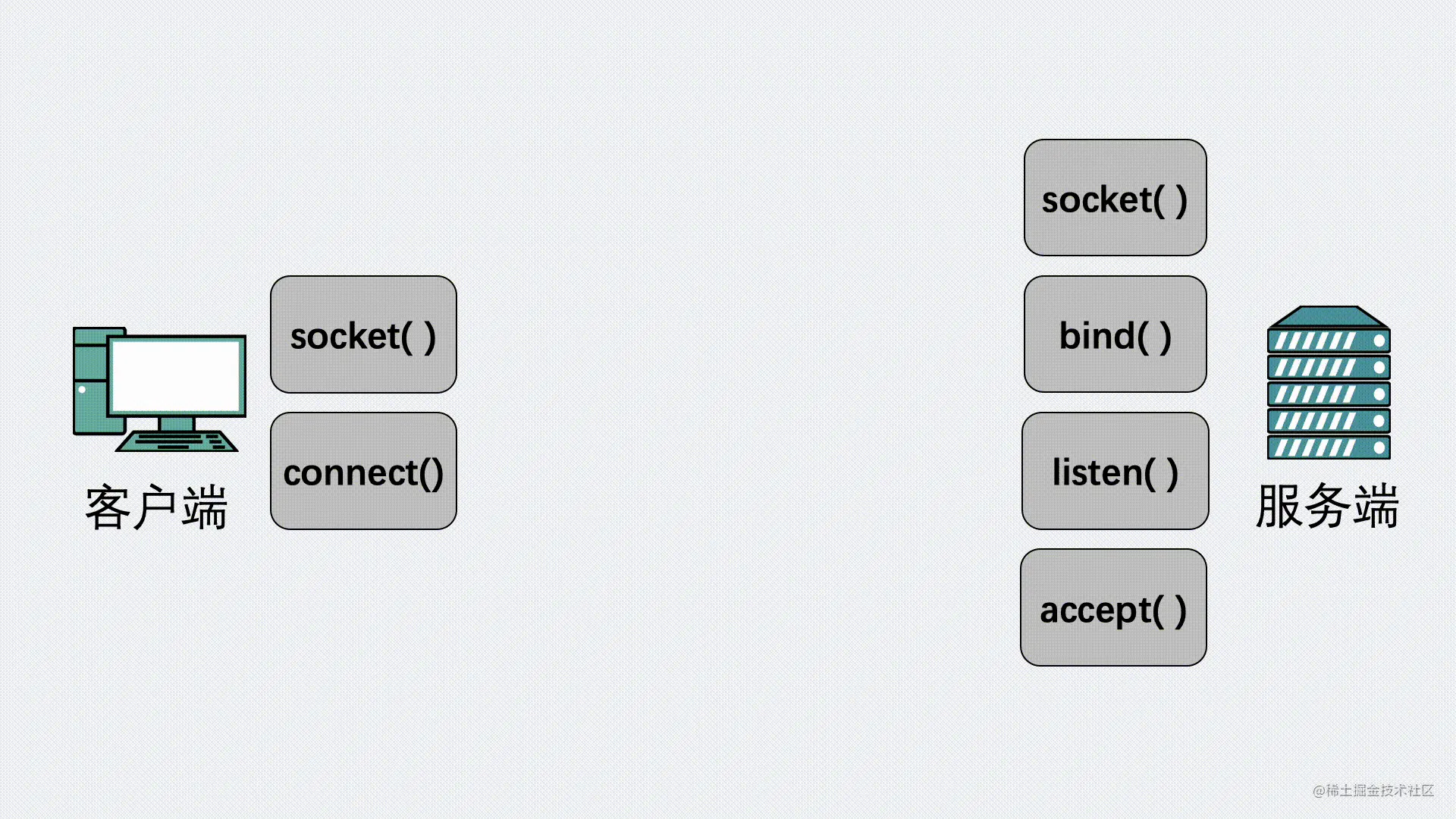
由于 HTTP 协议是基于 TCP 协议的,在应用层的数据封装好以后,要交给传输层,经 TCP 协议继续封装。
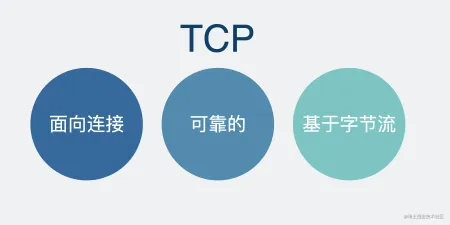
TCP 协议保证了数据传输的可靠性,是数据包传输的主力协议。
传送门:
网络层
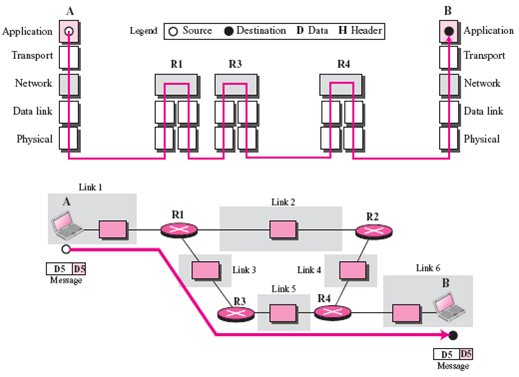
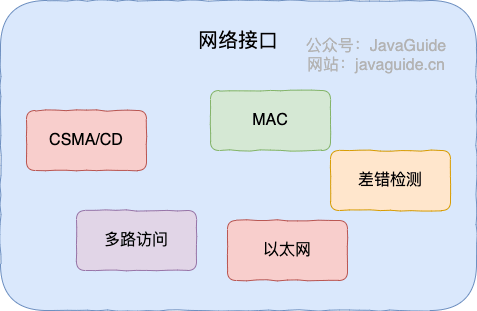
终于,来到网络层,此时我们的主机不再是和另一台主机进行交互了,而是在和中间系统进行交互。也就是说,应用层和传输层都是端到端的协议,而网络层及以下都是中间件的协议了。
网络层的的核心功能——转发与路由,必会!!!如果面试官问到了网络层,而你恰好又什么都不会的话,最最起码要说出这五个字——转发与路由。
- 转发:将分组从路由器的输入端口转移到合适的输出端口。
- 路由:确定分组从源到目的经过的路径。
所以到目前为止,我们的数据包经过了应用层、传输层的封装,来到了网络层,终于开始准备在物理层面传输了,第一个要解决的问题就是——往哪里传输?或者说,要把数据包发到哪个路由器上? 这便是 BGP 协议要解决的问题。