乐观锁和悲观锁的介绍以及乐观锁常见实现方式可以阅读笔者写的这篇文章:乐观锁和悲观锁详解。
这篇文章主要介绍 :Java 中 CAS 的实现以及 CAS 存在的一些问题。
Java 中 CAS 是如何实现的?
在 Java 中,实现 CAS(Compare-And-Swap, 比较并交换)操作的一个关键类是Unsafe。
Unsafe类位于sun.misc包下,是一个提供低级别、不安全操作的类。由于其强大的功能和潜在的危险性,它通常用于 JVM 内部或一些需要极高性能和底层访问的库中,而不推荐普通开发者在应用程序中使用。关于 Unsafe类的详细介绍,可以阅读这篇文章:📌Java 魔法类 Unsafe 详解。
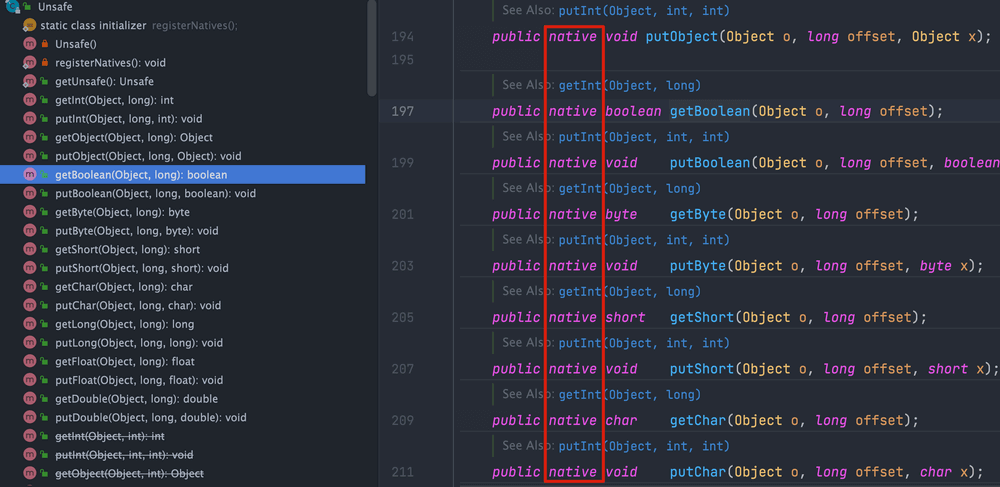
sun.misc包下的Unsafe类提供了compareAndSwapObject、compareAndSwapInt、compareAndSwapLong方法来实现的对Object、int、long类型的 CAS 操作:
1 | /** |
Unsafe类中的 CAS 方法是native方法。native关键字表明这些方法是用本地代码(通常是 C 或 C++)实现的,而不是用 Java 实现的。这些方法直接调用底层的硬件指令来实现原子操作。也就是说,Java 语言并没有直接用 Java 实现 CAS。
更准确点来说,Java 中 CAS 是 C++ 内联汇编的形式实现的,通过 JNI(Java Native Interface) 调用。因此,CAS 的具体实现与操作系统以及 CPU 密切相关。
java.util.concurrent.atomic 包提供了一些用于原子操作的类。
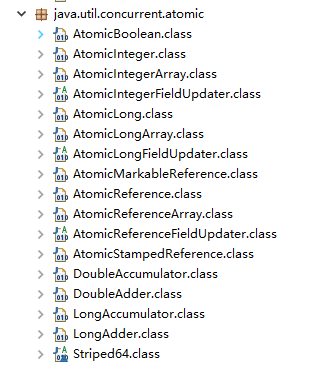
关于这些 Atomic 原子类的介绍和使用,可以阅读这篇文章:Atomic 原子类总结。
Atomic 类依赖于 CAS 乐观锁来保证其方法的原子性,而不需要使用传统的锁机制(如 synchronized 块或 ReentrantLock)。
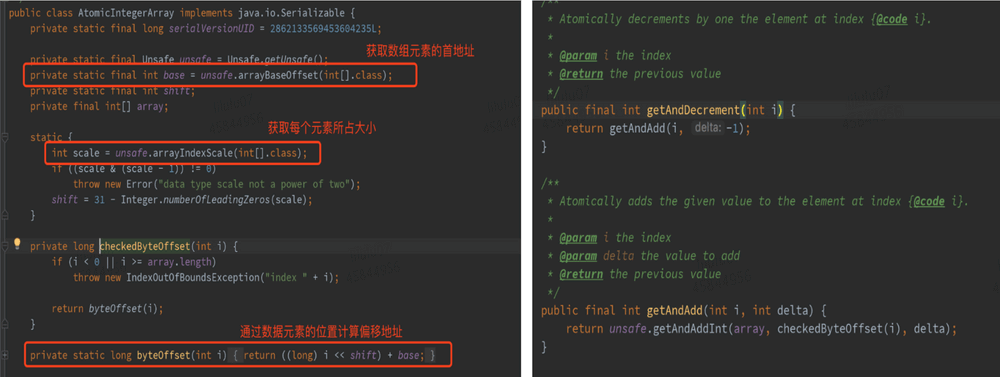
AtomicInteger是 Java 的原子类之一,主要用于对 int 类型的变量进行原子操作,它利用Unsafe类提供的低级别原子操作方法实现无锁的线程安全性。
下面,我们通过解读AtomicInteger的核心源码(JDK1.8),来说明 Java 如何使用Unsafe类的方法来实现原子操作。
AtomicInteger核心源码如下:
1 | // 获取 Unsafe 实例 |
Unsafe#getAndAddInt源码:
1 | // 原子地获取并增加整数值 |
可以看到,getAndAddInt 使用了 do-while 循环:在compareAndSwapInt操作失败时,会不断重试直到成功。也就是说,getAndAddInt方法会通过 compareAndSwapInt 方法来尝试更新 value 的值,如果更新失败(当前值在此期间被其他线程修改),它会重新获取当前值并再次尝试更新,直到操作成功。
由于 CAS 操作可能会因为并发冲突而失败,因此通常会与while循环搭配使用,在失败后不断重试,直到操作成功。这就是 自旋锁机制 。
CAS 算法存在哪些问题?
ABA 问题是 CAS 算法最常见的问题。
ABA 问题
如果一个变量 V 初次读取的时候是 A 值,并且在准备赋值的时候检查到它仍然是 A 值,那我们就能说明它的值没有被其他线程修改过了吗?很明显是不能的,因为在这段时间它的值可能被改为其他值,然后又改回 A,那 CAS 操作就会误认为它从来没有被修改过。这个问题被称为 CAS 操作的 “ABA”问题。
ABA 问题的解决思路是在变量前面追加上版本号或者时间戳。JDK 1.5 以后的 AtomicStampedReference 类就是用来解决 ABA 问题的,其中的 compareAndSet() 方法就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
1 | public boolean compareAndSet(V expectedReference, |
循环时间长开销大
CAS 经常会用到自旋操作来进行重试,也就是不成功就一直循环执行直到成功。如果长时间不成功,会给 CPU 带来非常大的执行开销。
如果 JVM 能够支持处理器提供的pause指令,那么自旋操作的效率将有所提升。pause指令有两个重要作用:
- 延迟流水线执行指令:
pause指令可以延迟指令的执行,从而减少 CPU 的资源消耗。具体的延迟时间取决于处理器的实现版本,在某些处理器上,延迟时间可能为零。 - 避免内存顺序冲突:在退出循环时,
pause指令可以避免由于内存顺序冲突而导致的 CPU 流水线被清空,从而提高 CPU 的执行效率。
只能保证一个共享变量的原子操作
CAS 操作仅能对单个共享变量有效。当需要操作多个共享变量时,CAS 就显得无能为力。不过,从 JDK 1.5 开始,Java 提供了AtomicReference类,这使得我们能够保证引用对象之间的原子性。通过将多个变量封装在一个对象中,我们可以使用AtomicReference来执行 CAS 操作。
除了 AtomicReference 这种方式之外,还可以利用加锁来保证。
总结
在 Java 中,CAS 通过 Unsafe 类中的 native 方法实现,这些方法调用底层的硬件指令来完成原子操作。由于其实现依赖于 C++ 内联汇编和 JNI 调用,因此 CAS 的具体实现与操作系统以及 CPU 密切相关。
CAS 虽然具有高效的无锁特性,但也需要注意 ABA 、循环时间长开销大等问题。



%E5%AE%9E%E4%BE%8B.jpg)