本文来自公众号:末读代码的投稿,原文地址:https://mp.weixin.qq.com/s/AHWzboztt53ZfFZmsSnMSw 。
上一篇文章介绍了 HashMap 源码,反响不错,也有很多同学发表了自己的观点,这次又来了,这次是 ConcurrentHashMap 了,作为线程安全的 HashMap ,它的使用频率也是很高。那么它的存储结构和实现原理是怎么样的呢?
1. ConcurrentHashMap 1.7
1. 存储结构
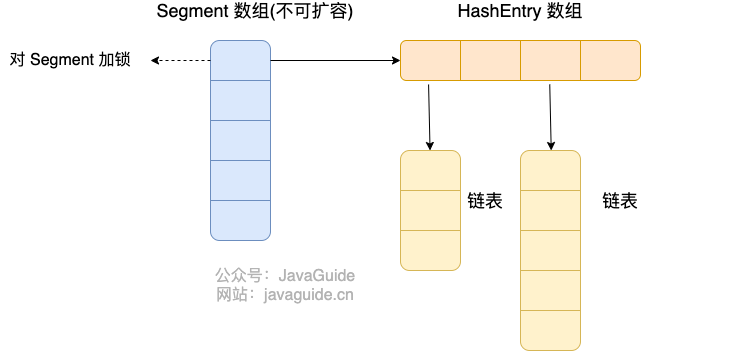
Java 7 中 ConcurrentHashMap 的存储结构如上图,ConcurrnetHashMap 由很多个 Segment 组合,而每一个 Segment 是一个类似于 HashMap 的结构,所以每一个 HashMap 的内部可以进行扩容。但是 Segment 的个数一旦初始化就不能改变,默认 Segment 的个数是 16 个,你也可以认为 ConcurrentHashMap 默认支持最多 16 个线程并发。
2. 初始化
通过 ConcurrentHashMap 的无参构造探寻 ConcurrentHashMap 的初始化流程。
1 | /** |
无参构造中调用了有参构造,传入了三个参数的默认值,他们的值是。
1 | /** |
接着看下这个有参构造函数的内部实现逻辑。
1 |
|
总结一下在 Java 7 中 ConcurrentHashMap 的初始化逻辑。
- 必要参数校验。
- 校验并发级别
concurrencyLevel大小,如果大于最大值,重置为最大值。无参构造默认值是 16. - 寻找并发级别
concurrencyLevel之上最近的 2 的幂次方值,作为初始化容量大小,默认是 16。 - 记录
segmentShift偏移量,这个值为【容量 = 2 的 N 次方】中的 N,在后面 Put 时计算位置时会用到。默认是 32 - sshift = 28. - 记录
segmentMask,默认是 ssize - 1 = 16 -1 = 15. - 初始化
segments[0],默认大小为 2,负载因子 0.75,扩容阀值是 2*0.75=1.5,插入第二个值时才会进行扩容。
3. put
接着上面的初始化参数继续查看 put 方法源码。
1 | /** |
上面的源码分析了 ConcurrentHashMap 在 put 一个数据时的处理流程,下面梳理下具体流程。
计算要 put 的 key 的位置,获取指定位置的
Segment。如果指定位置的
Segment为空,则初始化这个Segment.初始化 Segment 流程:
- 检查计算得到的位置的
Segment是否为 null. - 为 null 继续初始化,使用
Segment[0]的容量和负载因子创建一个HashEntry数组。 - 再次检查计算得到的指定位置的
Segment是否为 null. - 使用创建的
HashEntry数组初始化这个 Segment. - 自旋判断计算得到的指定位置的
Segment是否为 null,使用 CAS 在这个位置赋值为Segment.
- 检查计算得到的位置的
Segment.put插入 key,value 值。
上面探究了获取 Segment 段和初始化 Segment 段的操作。最后一行的 Segment 的 put 方法还没有查看,继续分析。
1 | final V put(K key, int hash, V value, boolean onlyIfAbsent) { |
由于 Segment 继承了 ReentrantLock,所以 Segment 内部可以很方便的获取锁,put 流程就用到了这个功能。
tryLock()获取锁,获取不到使用scanAndLockForPut方法继续获取。计算 put 的数据要放入的 index 位置,然后获取这个位置上的
HashEntry。遍历 put 新元素,为什么要遍历?因为这里获取的
HashEntry可能是一个空元素,也可能是链表已存在,所以要区别对待。如果这个位置上的
HashEntry不存在:- 如果当前容量大于扩容阀值,小于最大容量,进行扩容。
- 直接头插法插入。
如果这个位置上的
HashEntry存在:- 判断链表当前元素 key 和 hash 值是否和要 put 的 key 和 hash 值一致。一致则替换值
- 不一致,获取链表下一个节点,直到发现相同进行值替换,或者链表表里完毕没有相同的。
- 如果当前容量大于扩容阀值,小于最大容量,进行扩容。
- 直接链表头插法插入。
如果要插入的位置之前已经存在,替换后返回旧值,否则返回 null.
这里面的第一步中的 scanAndLockForPut 操作这里没有介绍,这个方法做的操作就是不断的自旋 tryLock() 获取锁。当自旋次数大于指定次数时,使用 lock() 阻塞获取锁。在自旋时顺表获取下 hash 位置的 HashEntry。
1 | private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) { |
4. 扩容 rehash
ConcurrentHashMap 的扩容只会扩容到原来的两倍。老数组里的数据移动到新的数组时,位置要么不变,要么变为 index+ oldSize,参数里的 node 会在扩容之后使用链表头插法插入到指定位置。
1 | private void rehash(HashEntry<K,V> node) { |
有些同学可能会对最后的两个 for 循环有疑惑,这里第一个 for 是为了寻找这样一个节点,这个节点后面的所有 next 节点的新位置都是相同的。然后把这个作为一个链表赋值到新位置。第二个 for 循环是为了把剩余的元素通过头插法插入到指定位置链表。这样实现的原因可能是基于概率统计,有深入研究的同学可以发表下意见。
内部第二个 for 循环中使用了 new HashEntry<K,V>(h, p.key, v, n) 创建了一个新的 HashEntry,而不是复用之前的,是因为如果复用之前的,那么会导致正在遍历(如正在执行 get 方法)的线程由于指针的修改无法遍历下去。正如注释中所说的:
当它们不再被可能正在并发遍历表的任何读取线程引用时,被替换的节点将被垃圾回收。
The nodes they replace will be garbage collectable as soon as they are no longer referenced by any reader thread that may be in the midst of concurrently traversing table
为什么需要再使用一个 for 循环找到 lastRun ,其实是为了减少对象创建的次数,正如注解中所说的:
从统计上看,在默认的阈值下,当表容量加倍时,只有大约六分之一的节点需要被克隆。
Statistically, at the default threshold, only about one-sixth of them need cloning when a table doubles.
5. get
到这里就很简单了,get 方法只需要两步即可。
- 计算得到 key 的存放位置。
- 遍历指定位置查找相同 key 的 value 值。
1 | public V get(Object key) { |
2. ConcurrentHashMap 1.8
1. 存储结构
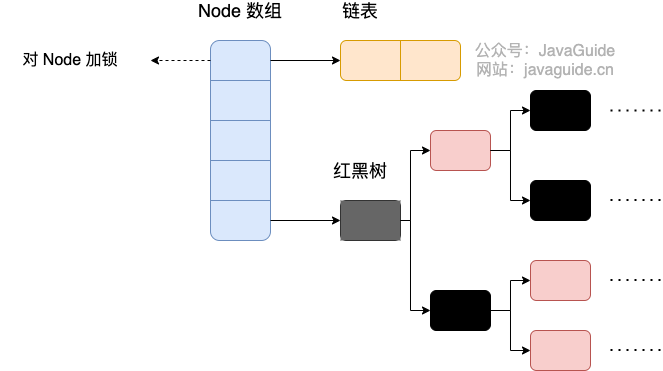
可以发现 Java8 的 ConcurrentHashMap 相对于 Java7 来说变化比较大,不再是之前的 Segment 数组 + HashEntry 数组 + 链表,而是 Node 数组 + 链表 / 红黑树。当冲突链表达到一定长度时,链表会转换成红黑树。
2. 初始化 initTable
1 | /** |
从源码中可以发现 ConcurrentHashMap 的初始化是通过自旋和 CAS 操作完成的。里面需要注意的是变量 sizeCtl (sizeControl 的缩写),它的值决定着当前的初始化状态。
- -1 说明正在初始化,其他线程需要自旋等待
- -N 说明 table 正在进行扩容,高 16 位表示扩容的标识戳,低 16 位减 1 为正在进行扩容的线程数
- 0 表示 table 初始化大小,如果 table 没有初始化
- >0 表示 table 扩容的阈值,如果 table 已经初始化。
3. put
直接过一遍 put 源码。
1 | public V put(K key, V value) { |
根据 key 计算出 hashcode 。
判断是否需要进行初始化。
即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
如果当前位置的
hashcode == MOVED == -1,则需要进行扩容。如果都不满足,则利用 synchronized 锁写入数据。
如果数量大于
TREEIFY_THRESHOLD则要执行树化方法,在treeifyBin中会首先判断当前数组长度 ≥64 时才会将链表转换为红黑树。
4. get
get 流程比较简单,直接过一遍源码。
1 | public V get(Object key) { |
总结一下 get 过程:
- 根据 hash 值计算位置。
- 查找到指定位置,如果头节点就是要找的,直接返回它的 value.
- 如果头节点 hash 值小于 0 ,说明正在扩容或者是红黑树,查找之。
- 如果是链表,遍历查找之。
总结:
总的来说 ConcurrentHashMap 在 Java8 中相对于 Java7 来说变化还是挺大的,
3. 总结
Java7 中 ConcurrentHashMap 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 Segment 都是一个类似 HashMap 数组的结构,它可以扩容,它的冲突会转化为链表。但是 Segment 的个数一但初始化就不能改变。
Java8 中的 ConcurrentHashMap 使用的 Synchronized 锁加 CAS 的机制。结构也由 Java7 中的 Segment 数组 + HashEntry 数组 + 链表 进化成了 Node 数组 + 链表 / 红黑树,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表。
有些同学可能对 Synchronized 的性能存在疑问,其实 Synchronized 锁自从引入锁升级策略后,性能不再是问题,有兴趣的同学可以自己了解下 Synchronized 的锁升级。