《计算机之魂》核心要点整理
《计算机之魂》核心要点整理
核心思维与原则
计算机思维的核心概念
- 递归:通过函数调用自身来解决问题,通常用于分解复杂问题为更小的子问题。
- 分治:将一个问题分解为多个较小规模的问题,分别求解后合并结果。
关键原则
等价性原理
- 等价转换:如书中P310所述,交换变量x和y的方法展示了如何利用等价性进行巧妙编程。例如,
x, x-1, 2x在某些情况下是等价的。 - 应用:等价性常用于将复杂状态简化,并间接解决难题,有助于归类和简化问题处理。
抽象化
- 模型构建:使用数学模型、数据结构或编码方式将现实问题转化为可计算的形式。
- 示例:从具体问题中抽象出不同的状态,并理解它们之间的转换关系。
平衡艺术
- 精度与范围:计算机表示浮点数时需平衡数值精度和表达范围,采用近似值以适应存储限制。
- 权衡策略:在不同场景下(如粗调+精调)做出适当的权衡,确保效率与效果的最优结合。
分类逻辑
- 智能问题的本质:很多问题可以归结为分类问题,包括分类、组织、查找和重组。
- 桥梁理论:第一座桥梁是将实际问题转换为信息处理中的分类问题;第二座桥梁是解决这些分类问题。
- 集合边界确认:
- 二叉判断:如二分决策树、M叉树(如B+树)。
- 枚举元素:如哈希表直接列出集合中的成员。
存储理论和技术
数据访问模式
- 特点导向:根据数据使用特点(顺序访问/随机访问)和获取量(大量/单个)选择合适的存储设备。
- 层次结构:围绕存储系统的层次展开讨论,考虑缓存、内存、磁盘等不同层级的作用。
多路归并与排序算法
- 多路归并:用于处理n个有序序列的合并问题,如找出前几名元素。
- 快速排序分割:适用于解决中值问题或比例划分问题。
图论及其应用
图的基本概念
- 点与线的关系:图是对离散、有限集合元素间关系的描述,广泛应用于最短路径、最大流、匹配等问题。
图的遍历方法
- 深度优先遍历:生成图的生成树,探索所有可能路径。
- 连通性分析:检查图中节点间的可达性。
最短路径与最大流
- 动态规划:一种常用算法,用于求解最短路径问题。
- 等价问题:最大流问题与最大配对问题在一定条件下是等价的。
确定性与随机性
概率算法的应用
- 世界本质:不确定性是固有的,概率算法能够有效应对这种特性。
- 量子通信安全:依赖于随机性来保证安全性。
- 置信度权衡:在成本与效果之间寻找最佳平衡点。
排序优化
蒂姆排序(Timsort)
- 混合排序法:结合了插入排序(节省内存)和归并排序(节省时间)的优点,是一种高效的排序算法。
数学特性
对数函数特征
- 分辨率变化:对数函数对较小数字提供高分辨率,而对较大数字则分辨率较低,这反映了其非线性的增长模式。
进程、线程、协程
参考https://blog.csdn.net/xushiyu1996818/article/details/106590789
同一个进程内的线程切换比进程切换快,因为线程具有相同的地址空间(虚拟内存共享),这意味着同一个进程的线程都具有同一个页表,那么在切换的时候不需要切换页表。而对于进程之间的切换,切换的时候要把页表给切换掉,而页表的切换过程开销是比较大的;

进程上下文 操作系统中把进程物理实体和支持进程运行的环境合称为进程上下文。
进程在其当前上下文中运行,当系统调度新进程占有处理器时,新老进程随之发生上下文切换。即保存老进程状态而装入被保护了的新进程的状态,以便新进程运行
进程上下文组成
用户级上下文:由正文(程序)、数据、共享存储区、用户栈组成,占用进程的虚地址空间。
存器上下文:由程序状态字寄存器、指令计数器、栈指针、控制寄存器、通用寄存器等组成。
系统级上下文:由进程控制块、主存管理信息(页表或段表)、核心栈等组成。
CPU 上下文切换
大多数操作系统都是多任务,通常支持大于 CPU 数量的任务同时运行。实际上,这些任务并不是同时运行的,只是因为系统在很短的时间内,让各个任务分别在 CPU 运行,于是就造成同时运行的错误。
任务是交给 CPU 运行的,那么在每个任务运行前,CPU 需要知道任务从哪里加载,又从哪里开始运行。
所以,操作系统需要事先帮 CPU 设置好 CPU 寄存器和程序计数器。
CPU 寄存器是 CPU 内部一个容量小,但是速度极快的内存(缓存)。我举个例子,寄存器像是你的口袋,内存像你的书包,硬盘则是你家里的柜子,如果你的东西存放到口袋,那肯定是比你从书包或家里柜子取出来要快的多。
再来,程序计数器则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。
所以说,CPU 寄存器和程序计数是 CPU 在运行任何任务前,所必须依赖的环境,这些环境就叫做 CPU 上下文。
既然知道了什么是 CPU 上下文,那理解 CPU 上下文切换就不难了。
CPU 上下文切换就是先把前一个任务的 CPU 上下文(CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
系统内核会存储保持下来的上下文信息,当此任务再次被分配给 CPU 运行时,CPU 会重新加载这些上下文,这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
上面说到所谓的「任务」,主要包含进程、线程和中断。所以,可以根据任务的不同,***==把 CPU 上下文切换分成:进程上下文切换、线程上下文切换和中断上下文切换。==***
进程的上下文切换到底是切换什么呢?
进程是由内核管理和调度的,所以进程的切换只能发生在内核态。
所以,进程的上下文切换不仅包含了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的资源。
通常,会把交换的信息保存在进程的 PCB,当要运行另外一个进程的时候,我们需要从这个进程的 PCB 取出上下文,然后恢复到 CPU 中,这使得这个进程可以继续执行,如下图所示:
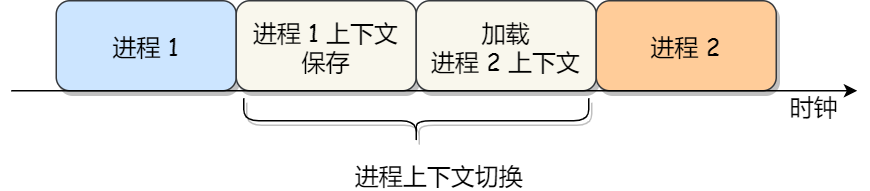
大家需要注意,进程的上下文开销是很关键的,我们希望它的开销越小越好,这样可以使得进程可以把更多时间花费在执行程序上,而不是耗费在上下文切换。
原文链接:https://blog.csdn.net/xushiyu1996818/article/details/106590789
回溯
描述
回溯其实就是暴力搜索,其思路是dfs。
回溯法思路的简单描述是:把问题的解空间转化成了图或者树的结构表示,然后使用**深度优先搜索策略**进行遍历,遍历的过程中记录和寻找所有可行解或者最优解。
分类
解空间树分为两种:**子集树和排列树**。两种在算法结构和思路上大体相同。
排列就是遍历所有空间,需要标记是否遍历过;for(i=0)
组合和子集其实是一类问题,只用遍历同一层还没遍历的,因此可以省去标记,for(i=start)
不同的是子集问题是,只要遍历一个点,就将当前符合要求的路径添加到最终答案中。
回溯法模板:
1 | void backtrack(参数) { |
对于需要去重的回溯问题:
(1)排列:
for(int i = 0; i < nums.length; i++){
//若在同一层已经遍历过(就是循环过了),则跳过这次
if(i > 1 && nums[i] == nums[i-1] && !used[i - 1]) continue;
(2)子集和组合:
for(inti=start;i<nums.length;i++){
if(i>start&&nums[i]==nums[i-1])continue;
题目
当问题是要求满足某种性质(约束条件)的所有解或最优解时,往往使用回溯法。
它有“通用解题法”之美誉。
- 子集问题lc78,lc90
- 排列问题lc46,lc47
- 组合求和问题lc39,40,216
- 分割回文串lc131
- 阿里快递最短路alibaba(DFS)
- 组合问题lc77【lc77中有对回溯法的优化,即剪枝】,lc401
- 二维平面上使用回溯法 lc79
- floodfill lc200(岛屿的个数),130,417
- N皇后问题lc51
- 数独问题lc37
股票问题通解
由于每天的情况都可以分为两种状态:买入和卖出,而这两种状态的收益和前一天的状态有关,因此构造动态规划的通用解。
在问题的进一步扩展上,增加了交易次数。
难点和关键在于找到状态之间的递推公式。
而动态规划的空间优化需要注意。
SQL常见面试题总结(3)
题目来源于:牛客题霸 - SQL 进阶挑战
较难或者困难的题目可以根据自身实际情况和面试需要来决定是否要跳过。
聚合函数
SQL 类别高难度试卷得分的截断平均值(较难)
描述: 牛客的运营同学想要查看大家在 SQL 类别中高难度试卷的得分情况。
请你帮她从exam_record数据表中计算所有用户完成 SQL 类别高难度试卷得分的截断平均值(去掉一个最大值和一个最小值后的平均值)。
示例数据:examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间)
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
| 2 | 9002 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
示例数据:exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分)
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
| 3 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:31:01 | 84 |
| 4 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
| 5 | 1001 | 9001 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 7 | 1002 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
| 8 | 1002 | 9001 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
| 9 | 1003 | 9001 | 2021-09-07 12:01:01 | 2021-09-07 10:31:01 | 50 |
| 10 | 1004 | 9001 | 2021-09-06 10:01:01 | (NULL) | (NULL) |
根据输入你的查询结果如下:
| tag | difficulty | clip_avg_score |
|---|---|---|
| SQL | hard | 81.7 |
从examination_info表可知,试卷 9001 为高难度 SQL 试卷,该试卷被作答的得分有[80,81,84,90,50],去除最高分和最低分后为[80,81,84],平均分为 81.6666667,保留一位小数后为 81.7
输入描述:
输入数据中至少有 3 个有效分数
思路一: 要找出高难度 sql 试卷,肯定需要联 examination_info 这张表,然后找出高难度的课程,由 examination_info 得知,高难度 sql 的 exam_id 为 9001,那么等下就以 exam_id = 9001 作为条件去查询;
先找出 9001 号考试 select * from exam_record where exam_id = 9001
然后,找出最高分 select max(score) 最高分 from exam_record where exam_id = 9001
接着,找出最低分 select min(score) 最低分 from exam_record where exam_id = 9001
在查询出来的分数结果集当中,去掉最高分和最低分,最直观能想到的就是 NOT IN 或者 用 NOT EXISTS 也行,这里以 NOT IN 来做
首先将主体写出来select tag, difficulty, round(avg(score), 1) clip_avg_score from examination_info info INNER JOIN exam_record record
小 tips : MYSQL 的 ROUND() 函数 ,ROUND(X)返回参数 X 最近似的整数 ROUND(X,D)返回 X ,其值保留到小数点后 D 位,第 D 位的保留方式为四舍五入。
再将上面的 “碎片” 语句拼凑起来即可, 注意在 NOT IN 中两个子查询用 UNION ALL 来关联,用 union 把 max 和 min 的结果集中在一行当中,这样形成一列多行的效果。
答案一:
1 | SELECT tag, difficulty, ROUND(AVG(score), 1) clip_avg_score |
这是最直观,也是最容易想到的解法,但是还有待改进,这算是投机取巧过关,其实严格按照题目要求应该这么写:
1 | SELECT tag, |
然而你会发现,重复的语句非常多,所以可以利用WITH来抽取公共部分
WITH 子句介绍:
WITH 子句,也称为公共表表达式(Common Table Expression,CTE),是在 SQL 查询中定义临时表的方式。它可以让我们在查询中创建一个临时命名的结果集,并且可以在同一查询中引用该结果集。
基本用法:
1 | WITH cte_name (column1, column2, ..., columnN) AS ( |
WITH 子句由以下几个部分组成:
cte_name: 给临时表起一个名称,可以在主查询中引用。(column1, column2, ..., columnN): 可选,指定临时表的列名。AS: 必需,表示开始定义临时表。CTE 查询体: 实际的查询语句,用于定义临时表中的数据。
WITH 子句的主要用途之一是增强查询的可读性和可维护性,尤其在涉及多个嵌套子查询或需要重复使用相同的查询逻辑时。通过将这些逻辑放在一个命名的临时表中,我们可以更清晰地组织查询,并消除重复代码。
此外,WITH 子句还可以在复杂的查询中实现递归查询。递归查询允许我们在单个查询中执行对同一表的多次迭代,逐步构建结果集。这在处理层次结构数据、组织结构和树状结构等场景中非常有用。
小细节:MySQL 5.7 版本以及之前的版本不支持在 WITH 子句中直接使用别名。
下面是改进后的答案:
1 | WITH t1 AS |
思路二:
- 筛选 SQL 高难度试卷:
where tag="SQL" and difficulty="hard" - 计算截断平均值:
(和-最大值-最小值) / (总个数-2):(sum(score) - max(score) - min(score)) / (count(score) - 2)- 有一个缺点就是,如果最大值和最小值有多个,这个方法就很难筛选出来, 但是题目中说了—–>
去掉一个最大值和一个最小值后的平均值, 所以这里可以用这个公式。
答案二:
1 | SELECT info.tag, |
统计作答次数
有一个试卷作答记录表 exam_record,请从中统计出总作答次数 total_pv、试卷已完成作答数 complete_pv、已完成的试卷数 complete_exam_cnt。
示例数据 exam_record 表(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
| 3 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:31:01 | 84 |
| 4 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
| 5 | 1001 | 9001 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 7 | 1002 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
| 8 | 1002 | 9001 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
| 9 | 1003 | 9001 | 2021-09-07 12:01:01 | 2021-09-07 10:31:01 | 50 |
| 10 | 1004 | 9001 | 2021-09-06 10:01:01 | (NULL) | (NULL) |
示例输出:
| total_pv | complete_pv | complete_exam_cnt |
|---|---|---|
| 10 | 7 | 2 |
解释:表示截止当前,有 10 次试卷作答记录,已完成的作答次数为 7 次(中途退出的为未完成状态,其交卷时间和份数为 NULL),已完成的试卷有 9001 和 9002 两份。
思路: 这题一看到统计次数,肯定第一时间就要想到用COUNT这个函数来解决,问题是要统计不同的记录,该怎么来写?使用子查询就能解决这个题目(这题用 case when 也能写出来,解法类似,逻辑不同而已);首先在做这个题之前,让我们先来了解一下COUNT的基本用法;
COUNT() 函数的基本语法如下所示:
1 | COUNT(expression) |
其中,expression 可以是列名、表达式、常量或通配符。下面是一些常见的用法示例:
- 计算表中所有行的数量:
1 | SELECT COUNT(*) FROM table_name; |
- 计算特定列非空(不为 NULL)值的数量:
1 | SELECT COUNT(column_name) FROM table_name; |
- 计算满足条件的行数:
1 | SELECT COUNT(*) FROM table_name WHERE condition; |
- 结合
GROUP BY使用,计算分组后每个组的行数:
1 | SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name; |
- 计算不同列组合的唯一组合数:
1 | SELECT COUNT(DISTINCT column_name1, column_name2) FROM table_name; |
在使用 COUNT() 函数时,如果不指定任何参数或者使用 COUNT(*),将会计算所有行的数量。而如果使用列名,则只会计算该列非空值的数量。
另外,COUNT() 函数的结果是一个整数值。即使结果是零,也不会返回 NULL,这点需要谨记。
答案:
1 | SELECT |
这里着重说一下COUNT( DISTINCT exam_id, score IS NOT NULL OR NULL )这一句,判断 score 是否为 null ,如果是即为真,如果不是返回 null;注意这里如果不加 or null 在不是 null 的情况下只会返回 false 也就是返回 0;
COUNT本身是不可以对多列求行数的,distinct的加入是的多列成为一个整体,可以求出现的行数了;count distinct在计算时只返回非 null 的行, 这个也要注意;
另外通过本题 get 到了——>count 加条件常用句式count( 列判断 or null)
得分不小于平均分的最低分
描述: 请从试卷作答记录表中找到 SQL 试卷得分不小于该类试卷平均得分的用户最低得分。
示例数据 exam_record 表(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
| 4 | 1002 | 9003 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 5 | 1002 | 9001 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
| 6 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
| 7 | 1003 | 9002 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
| 8 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
| 9 | 1004 | 9003 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
examination_info 表(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间)
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
| 2 | 9002 | SQL | easy | 60 | 2020-02-01 10:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
示例输出数据:
| min_score_over_avg |
|---|
| 87 |
解释:试卷 9001 和 9002 为 SQL 类别,作答这两份试卷的得分有[80,89,87,90],平均分为 86.5,不小于平均分的最小分数为 87
思路:这类题目第一眼看确实很复杂, 因为不知道从哪入手,但是当我们仔细读题审题后,要学会抓住题干中的关键信息。以本题为例:请从试卷作答记录表中找到SQL试卷得分不小于该类试卷平均得分的用户最低得分。你能一眼从中提取哪些有效信息来作为解题思路?
第一条:找到==SQL==试卷得分
第二条:该类试卷==平均得分==
第三条:该类试卷的==用户最低得分==
然后中间的 “桥梁” 就是==不小于==
将条件拆分后,先逐步完成
1 | -- 找出tag为‘SQL’的得分 【80, 89,87,90】 |
然后再找出该类试卷的最低得分,接着将结果集【80, 89,87,90】 去和平均分数作比较,方可得出最终答案。
答案:
1 | SELECT MIN(score) AS min_score_over_avg |
其实这类题目给出的要求看似很 “绕”,但其实仔细梳理一遍,将大条件拆分成小条件,逐个拆分完以后,最后将所有条件拼凑起来。反正只要记住:抓主干,理分支,问题便迎刃而解。
分组查询
平均活跃天数和月活人数
描述:用户在牛客试卷作答区作答记录存储在表 exam_record 中,内容如下:
exam_record 表(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分)
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-07-02 09:21:01 | 80 |
| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
| 4 | 1002 | 9003 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 5 | 1002 | 9001 | 2021-07-02 19:01:01 | 2021-07-02 19:30:01 | 82 |
| 6 | 1002 | 9002 | 2021-07-05 18:01:01 | 2021-07-05 18:59:02 | 90 |
| 7 | 1003 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
| 8 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
| 9 | 1004 | 9003 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
| 10 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
| 11 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
| 12 | 1006 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
| 13 | 1007 | 9002 | 2020-09-02 12:11:01 | 2020-09-02 12:31:01 | 89 |
请计算 2021 年每个月里试卷作答区用户平均月活跃天数 avg_active_days 和月度活跃人数 mau,上面数据的示例输出如下:
| month | avg_active_days | mau |
|---|---|---|
| 202107 | 1.50 | 2 |
| 202109 | 1.25 | 4 |
解释:2021 年 7 月有 2 人活跃,共活跃了 3 天(1001 活跃 1 天,1002 活跃 2 天),平均活跃天数 1.5;2021 年 9 月有 4 人活跃,共活跃了 5 天,平均活跃天数 1.25,结果保留 2 位小数。
注:此处活跃指有==交卷==行为。
思路:读完题先注意高亮部分;一般求天数和月活跃人数马上就要想到相关的日期函数;这一题我们同样来进行拆分,把问题细化再解决;首先求活跃人数,肯定要用到COUNT(),那这里首先就有一个坑,不知道大家注意了没有?用户 1002 在 9 月份做了两种不同的试卷,所以这里要注意去重,不然在统计的时候,活跃人数是错的;第二个就是要知道日期的格式化,如上表,题目要求以202107这种日期格式展现,要用到DATE_FORMAT来进行格式化。
基本用法:
DATE_FORMAT(date_value, format)
date_value参数是待格式化的日期或时间值。format参数是指定的日期或时间格式(这个和 Java 里面的日期格式一样)。
答案:
1 | SELECT DATE_FORMAT(submit_time, '%Y%m') MONTH, |
这里多说一句, 使用COUNT(DISTINCT uid, DATE_FORMAT(submit_time, '%Y%m%d')) 可以统计在 uid 列和 submit_time 列按照年份、月份和日期进行格式化后的组合值的数量。
月总刷题数和日均刷题数
描述:现有一张题目练习记录表 practice_record,示例内容如下:
| id | uid | question_id | submit_time | score |
|---|---|---|---|---|
| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
| 5 | 1003 | 8002 | 2021-08-01 19:38:01 | 80 |
请从中统计出 2021 年每个月里用户的月总刷题数 month_q_cnt 和日均刷题数 avg_day_q_cnt(按月份升序排序)以及该年的总体情况,示例数据输出如下:
| submit_month | month_q_cnt | avg_day_q_cnt |
|---|---|---|
| 202108 | 2 | 0.065 |
| 202109 | 3 | 0.100 |
| 2021 汇总 | 5 | 0.161 |
解释:2021 年 8 月共有 2 次刷题记录,日均刷题数为 2/31=0.065(保留 3 位小数);2021 年 9 月共有 3 次刷题记录,日均刷题数为 3/30=0.100;2021 年共有 5 次刷题记录(年度汇总平均无实际意义,这里我们按照 31 天来算 5/31=0.161)
牛客已经采用最新的 Mysql 版本,如果您运行结果出现错误:ONLY_FULL_GROUP_BY,意思是:对于 GROUP BY 聚合操作,如果在 SELECT 中的列,没有在 GROUP BY 中出现,那么这个 SQL 是不合法的,因为列不在 GROUP BY 从句中,也就是说查出来的列必须在 group by 后面出现否则就会报错,或者这个字段出现在聚合函数里面。
思路:
看到实例数据就要马上联想到相关的函数,比如submit_month就要用到DATE_FORMAT来格式化日期。然后查出每月的刷题数量。
每月的刷题数量
1 | SELECT MONTH ( submit_time ), COUNT( question_id ) |
接着第三列这里要用到DAY(LAST_DAY(date_value))函数来查找给定日期的月份中的天数。
示例代码如下:
1 | SELECT DAY(LAST_DAY('2023-07-08')) AS days_in_month; |
使用 LAST_DAY() 函数获取给定日期的当月最后一天,然后使用 DAY() 函数提取该日期的天数。这样就能获得指定月份的天数。
需要注意的是,LAST_DAY() 函数返回的是日期值,而 DAY() 函数用于提取日期值中的天数部分。
有了上述的分析之后,即可马上写出答案,这题复杂就复杂在处理日期上,其中的逻辑并不难。
答案:
1 | SELECT DATE_FORMAT(submit_time, '%Y%m') submit_month, |
在实例数据输出中因为最后一行需要得出汇总数据,所以这里要 UNION ALL加到结果集中;别忘了最后要排序!
未完成试卷数大于 1 的有效用户(较难)
描述:现有试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分),示例数据如下:
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-07-02 09:21:01 | 80 |
| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
| 4 | 1002 | 9003 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 5 | 1002 | 9001 | 2021-07-02 19:01:01 | 2021-07-02 19:30:01 | 82 |
| 6 | 1002 | 9002 | 2021-07-05 18:01:01 | 2021-07-05 18:59:02 | 90 |
| 7 | 1003 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
| 8 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
| 9 | 1004 | 9003 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
| 10 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
| 11 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
| 12 | 1006 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
| 13 | 1007 | 9002 | 2020-09-02 12:11:01 | 2020-09-02 12:31:01 | 89 |
还有一张试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间),示例数据如下:
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
| 2 | 9002 | SQL | easy | 60 | 2020-02-01 10:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
请统计 2021 年每个未完成试卷作答数大于 1 的有效用户的数据(有效用户指完成试卷作答数至少为 1 且未完成数小于 5),输出用户 ID、未完成试卷作答数、完成试卷作答数、作答过的试卷 tag 集合,按未完成试卷数量由多到少排序。示例数据的输出结果如下:
| uid | incomplete_cnt | complete_cnt | detail |
|---|---|---|---|
| 1002 | 2 | 4 | 2021-09-01:算法;2021-07-02:SQL;2021-09-02:SQL;2021-09-05:SQL;2021-07-05:SQL |
解释:2021 年的作答记录中,除了 1004,其他用户均满足有效用户定义,但只有 1002 未完成试卷数大于 1,因此只输出 1002,detail 中是 1002 作答过的试卷{日期:tag}集合,日期和 tag 间用 : 连接,多元素间用 ; 连接。
思路:
仔细读题后,分析出:首先要联表,因为后面要输出tag;
筛选出 2021 年的数据
1 | SELECT * |
根据 uid 进行分组,然后对每个用户进行条件进行判断,题目中要求完成试卷数至少为1,未完成试卷数要大于1,小于5
那么等会儿写 sql 的时候条件应该是:未完成 > 1 and 已完成 >=1 and 未完成 < 5
因为最后要用到字符串的拼接,而且还要组合拼接,这个可以用GROUP_CONCAT函数,下面简单介绍一下该函数的用法:
基本格式:
1 | GROUP_CONCAT([DISTINCT] expr [ORDER BY {unsigned_integer | col_name | expr} [ASC | DESC] [, ...]] [SEPARATOR sep]) |
expr:要连接的列或表达式。DISTINCT:可选参数,用于去重。当指定了DISTINCT,相同的值只会出现一次。ORDER BY:可选参数,用于排序连接后的值。可以选择升序 (ASC) 或降序 (DESC) 排序。SEPARATOR sep:可选参数,用于设置连接后的值的分隔符。(本题要用这个参数设置 ; 号 )
GROUP_CONCAT() 函数常用于 GROUP BY 子句中,将一组行的值连接为一个字符串,并在结果集中以聚合的形式返回。
答案:
1 | SELECT a.uid, |
SUM(CASE WHEN a.submit_time IS NULL THEN 1 END)统计了每个用户未完成的记录数量。SUM(CASE WHEN a.submit_time IS NOT NULL THEN 1 END)统计了每个用户已完成的记录数量。GROUP_CONCAT(DISTINCT CONCAT(DATE_FORMAT(a.start_time, '%Y-%m-%d'), ':', b.tag) ORDER BY a.start_time SEPARATOR ';')将每个用户的考试日期和标签以逗号分隔的形式连接成一个字符串,并按考试开始时间进行排序。
嵌套子查询
月均完成试卷数不小于 3 的用户爱作答的类别(较难)
描述:现有试卷作答记录表 exam_record(uid:用户 ID, exam_id:试卷 ID, start_time:开始作答时间, submit_time:交卷时间,没提交的话为 NULL, score:得分),示例数据如下:
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | (NULL) | (NULL) |
| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | 2021-09-02 12:31:01 | 70 |
| 4 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
| 5 | 1002 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
| 6 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
| 7 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
| 8 | 1003 | 9001 | 2021-09-08 13:01:01 | (NULL) | (NULL) |
| 9 | 1003 | 9002 | 2021-09-08 14:01:01 | (NULL) | (NULL) |
| 10 | 1003 | 9003 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
| 11 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
| 12 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
| 13 | 1005 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
试卷信息表 examination_info(exam_id:试卷 ID, tag:试卷类别, difficulty:试卷难度, duration:考试时长, release_time:发布时间),示例数据如下:
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
| 2 | 9002 | C++ | easy | 60 | 2020-02-01 10:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
请从表中统计出 “当月均完成试卷数”不小于 3 的用户们爱作答的类别及作答次数,按次数降序输出,示例输出如下:
| tag | tag_cnt |
|---|---|
| C++ | 4 |
| SQL | 2 |
| 算法 | 1 |
解释:用户 1002 和 1005 在 2021 年 09 月的完成试卷数目均为 3,其他用户均小于 3;然后用户 1002 和 1005 作答过的试卷 tag 分布结果按作答次数降序排序依次为 C++、SQL、算法。
思路:这题考察联合子查询,重点在于月均回答>=3, 但是个人认为这里没有表述清楚,应该直接说查 9 月的就容易理解多了;这里不是每个月都要>=3 或者是所有答题次数/答题月份。不要理解错误了。
先查询出哪些用户月均答题大于三次
1 | SELECT UID |
有了这一步之后再进行深入,只要能理解上一步(我的意思是不被题目中的月均所困扰),然后再套一个子查询,查哪些用户包含其中,然后查出题目中所需的列即可。记得排序!!
1 | SELECT tag, |
试卷发布当天作答人数和平均分
描述:现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间),示例数据如下:
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 号 | 3100 | 7 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 2100 | 6 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 牛客 3 号 | 1500 | 5 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客 4 号 | 1100 | 4 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 牛客 5 号 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
| 6 | 1006 | 牛客 6 号 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
释义:用户 1001 昵称为牛客 1 号,成就值为 3100,用户等级是 7 级,职业方向为算法,注册时间 2020-01-01 10:00:00
试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间) 示例数据如下:
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
| 2 | 9002 | C++ | easy | 60 | 2020-02-01 10:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分) 示例数据如下:
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-09-01 09:41:01 | 70 |
| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | 2021-09-02 12:31:01 | 70 |
| 4 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 80 |
| 5 | 1002 | 9003 | 2021-08-01 12:01:01 | 2021-08-01 12:21:01 | 60 |
| 6 | 1002 | 9002 | 2021-08-02 12:01:01 | 2021-08-02 12:31:01 | 70 |
| 7 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 85 |
| 8 | 1002 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
| 9 | 1003 | 9002 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
| 10 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
| 11 | 1003 | 9003 | 2021-09-01 13:01:01 | 2021-09-01 13:41:01 | 70 |
| 12 | 1003 | 9001 | 2021-09-08 14:01:01 | (NULL) | (NULL) |
| 13 | 1003 | 9002 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
| 14 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 90 |
| 15 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
| 16 | 1005 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
请计算每张 SQL 类别试卷发布后,当天 5 级以上的用户作答的人数 uv 和平均分 avg_score,按人数降序,相同人数的按平均分升序,示例数据结果输出如下:
| exam_id | uv | avg_score |
|---|---|---|
| 9001 | 3 | 81.3 |
解释:只有一张 SQL 类别的试卷,试卷 ID 为 9001,发布当天(2021-09-01)有 1001、1002、1003、1005 作答过,但是 1003 是 5 级用户,其他 3 位为 5 级以上,他们三的得分有[70,80,85,90],平均分为 81.3(保留 1 位小数)。
思路:这题看似很复杂,但是先逐步将“外边”条件拆分,然后合拢到一起,答案就出来,多表查询反正记住:由外向里,抽丝剥茧。
先把三种表连起来,同时给定一些条件,比如题目中要求等级> 5的用户,那么可以先查出来
1 | SELECT DISTINCT u_info.uid |
接着注意题目中要求:每张sql类别试卷发布后,当天作答用户,注意其中的==当天==,那我们马上就要想到要用到时间的比较。
对试卷发布日期和开始考试日期进行比较:DATE(e_info.release_time) = DATE(record.start_time);不用担心submit_time 为 null 的问题,后续在 where 中会给过滤掉。
答案:
1 | SELECT record.exam_id AS exam_id, |
注意最后的分组排序!先按人数排,若一致,按平均分排。
作答试卷得分大于过 80 的人的用户等级分布
描述:
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 号 | 3100 | 7 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 2100 | 6 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 牛客 3 号 | 1500 | 5 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客 4 号 | 1100 | 4 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 牛客 5 号 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
| 6 | 1006 | 牛客 6 号 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间):
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
| 2 | 9002 | C++ | easy | 60 | 2021-09-01 06:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
试卷作答信息表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:41:01 | 79 |
| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
| 3 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
| 4 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 80 |
| 5 | 1002 | 9003 | 2021-08-01 12:01:01 | 2021-08-01 12:21:01 | 60 |
| 6 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
| 7 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 85 |
| 8 | 1002 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 9 | 1003 | 9002 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
| 10 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
| 11 | 1003 | 9003 | 2021-09-01 13:01:01 | 2021-09-01 13:41:01 | 81 |
| 12 | 1003 | 9001 | 2021-09-01 14:01:01 | (NULL) | (NULL) |
| 13 | 1003 | 9002 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
| 14 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 90 |
| 15 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
| 16 | 1005 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
统计作答 SQL 类别的试卷得分大于过 80 的人的用户等级分布,按数量降序排序(保证数量都不同)。示例数据结果输出如下:
| level | level_cnt |
|---|---|
| 6 | 2 |
| 5 | 1 |
解释:9001 为 SQL 类试卷,作答该试卷大于 80 分的人有 1002、1003、1005 共 3 人,6 级两人,5 级一人。
思路:这题和上一题都是一样的数据,只是查询条件改变了而已,上一题理解了,这题分分钟做出来。
答案:
1 | SELECT u_info.LEVEL AS LEVEL, |
合并查询
每个题目和每份试卷被作答的人数和次数
描述:
现有试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:41:01 | 81 |
| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
| 3 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 80 |
| 4 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
| 5 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 85 |
| 6 | 1002 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
题目练习表 practice_record(uid 用户 ID, question_id 题目 ID, submit_time 提交时间, score 得分):
| id | uid | question_id | submit_time | score |
|---|---|---|---|---|
| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
| 5 | 1003 | 8001 | 2021-08-02 19:38:01 | 70 |
| 6 | 1003 | 8001 | 2021-08-02 19:48:01 | 90 |
| 7 | 1003 | 8002 | 2021-08-01 19:38:01 | 80 |
请统计每个题目和每份试卷被作答的人数和次数,分别按照”试卷”和”题目”的 uv & pv 降序显示,示例数据结果输出如下:
| tid | uv | pv |
|---|---|---|
| 9001 | 3 | 3 |
| 9002 | 1 | 3 |
| 8001 | 3 | 5 |
| 8002 | 2 | 2 |
解释:“试卷”有 3 人共练习 3 次试卷 9001,1 人作答 3 次 9002;“刷题”有 3 人刷 5 次 8001,有 2 人刷 2 次 8002
思路:这题的难点和易错点在于UNION和ORDER BY 同时使用的问题
有以下几种情况:使用union和多个order by不加括号,报错!
order by在union连接的子句中不起作用;
比如不加括号:
1 | SELECT exam_id AS tid, |
直接报语法错误,如果没有括号,只能有一个order by
还有一种order by不起作用的情况,但是能在子句的子句中起作用,这里的解决方案就是在外面再套一层查询。
答案:
1 | SELECT * |
分别满足两个活动的人
描述: 为了促进更多用户在牛客平台学习和刷题进步,我们会经常给一些既活跃又表现不错的用户发放福利。假使以前我们有两拨运营活动,分别给每次试卷得分都能到 85 分的人(activity1)、至少有一次用了一半时间就完成高难度试卷且分数大于 80 的人(activity2)发了福利券。
现在,需要你一次性将这两个活动满足的人筛选出来,交给运营同学。请写出一个 SQL 实现:输出 2021 年里,所有每次试卷得分都能到 85 分的人以及至少有一次用了一半时间就完成高难度试卷且分数大于 80 的人的 id 和活动号,按用户 ID 排序输出。
现有试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间):
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
| 2 | 9002 | C++ | easy | 60 | 2021-09-01 06:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
| 3 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 86 |
| 4 | 1003 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 89 |
| 5 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
示例数据输出结果:
| uid | activity |
|---|---|
| 1001 | activity2 |
| 1003 | activity1 |
| 1004 | activity1 |
| 1004 | activity2 |
解释:用户 1001 最小分数 81 不满足活动 1,但 29 分 59 秒完成了 60 分钟长的试卷得分 81,满足活动 2;1003 最小分数 86 满足活动 1,完成时长都大于试卷时长的一半,不满足活动 2;用户 1004 刚好用了一半时间(30 分钟整)完成了试卷得分 85,满足活动 1 和活动 2。
思路: 这一题需要涉及到时间的减法,需要用到 TIMESTAMPDIFF() 函数计算两个时间戳之间的分钟差值。
下面我们来看一下基本用法
示例:
1 | TIMESTAMPDIFF(MINUTE, start_time, end_time) |
TIMESTAMPDIFF() 函数的第一个参数是时间单位,这里我们选择 MINUTE 表示返回分钟差值。第二个参数是较早的时间戳,第三个参数是较晚的时间戳。函数会返回它们之间的分钟差值
了解了这个函数的用法之后,我们再回过头来看activity1的要求,求分数大于 85 即可,那我们还是先把这个写出来,后续思路就会清晰很多
1 | SELECT DISTINCT UID |
根据条件 2,接着写出在一半时间内完成高难度试卷且分数大于80的人
1 | SELECT UID |
然后再把两者UNION 起来即可。(这里特别要注意括号问题和order by位置,具体用法在上一篇中已提及)
答案:
1 | SELECT DISTINCT UID UID, |
连接查询
满足条件的用户的试卷完成数和题目练习数(困难)
描述:
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 号 | 3100 | 7 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 2300 | 7 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 牛客 3 号 | 2500 | 7 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客 4 号 | 1200 | 5 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 牛客 5 号 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
| 6 | 1006 | 牛客 6 号 | 2000 | 6 | C++ | 2020-01-01 10:00:00 |
试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间):
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
| 2 | 9002 | C++ | hard | 60 | 2021-09-01 06:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
| 3 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 86 |
| 4 | 1003 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:51 | 89 |
| 5 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
| 6 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:02 | 85 |
| 7 | 1006 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 84 |
| 8 | 1006 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 80 |
题目练习记录表 practice_record(uid 用户 ID, question_id 题目 ID, submit_time 提交时间, score 得分):
| id | uid | question_id | submit_time | score |
|---|---|---|---|---|
| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
| 5 | 1004 | 8001 | 2021-08-02 19:38:01 | 70 |
| 6 | 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
| 7 | 1001 | 8002 | 2021-08-02 19:38:01 | 70 |
| 8 | 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
| 9 | 1004 | 8002 | 2021-08-02 19:58:01 | 94 |
| 10 | 1004 | 8003 | 2021-08-02 19:38:01 | 70 |
| 11 | 1004 | 8003 | 2021-08-02 19:48:01 | 90 |
| 12 | 1004 | 8003 | 2021-08-01 19:38:01 | 80 |
请你找到高难度 SQL 试卷得分平均值大于 80 并且是 7 级的红名大佬,统计他们的 2021 年试卷总完成次数和题目总练习次数,只保留 2021 年有试卷完成记录的用户。结果按试卷完成数升序,按题目练习数降序。
示例数据输出如下:
| uid | exam_cnt | question_cnt |
|---|---|---|
| 1001 | 1 | 2 |
| 1003 | 2 | 0 |
解释:用户 1001、1003、1004、1006 满足高难度 SQL 试卷得分平均值大于 80,但只有 1001、1003 是 7 级红名大佬;1001 完成了 1 次试卷 1001,练习了 2 次题目;1003 完成了 2 次试卷 9001、9002,未练习题目(因此计数为 0)
思路:
先将条件进行初步筛选,比如先查出做过高难度 sql 试卷的用户
1 | SELECT |
然后根据题目要求,接着再往里叠条件即可;
但是这里又要注意:
第一:不能YEAR(submit_time)= 2021这个条件放到最后,要在ON条件里,因为左连接存在返回左表全部行,右表为 null 的情形,放在 JOIN条件的 ON 子句中的目的是为了确保在连接两个表时,只有满足年份条件的记录会进行连接。这样可以避免其他年份的记录被包含在结果中。即 1001 做过 2021 年的试卷,但没有练习过,如果把条件放到最后,就会排除掉这种情况。
第二,必须是COUNT(distinct er.exam_id) exam_cnt, COUNT(distinct pr.id) question_cnt,要加 distinct,因为有左连接产生很多重复值。
答案:
1 | SELECT er.uid AS UID, |
可能细心的小伙伴会发现,为什么明明将条件限制了tag = 'SQL' AND difficulty = 'hard',但是用户 1003 仍然能查出两条考试记录,其中一条的考试tag为 C++; 这是由于LEFT JOIN的特性,即使没有与右表匹配的行,左表的所有记录仍然会被保留。
每个 6/7 级用户活跃情况(困难)
描述:
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 号 | 3100 | 7 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 2300 | 7 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 牛客 3 号 | 2500 | 7 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客 4 号 | 1200 | 5 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 牛客 5 号 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
| 6 | 1006 | 牛客 6 号 | 2600 | 7 | C++ | 2020-01-01 10:00:00 |
试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间):
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
| 2 | 9002 | C++ | easy | 60 | 2021-09-01 06:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|
| 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 78 |
| 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
| 1005 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
| 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:02 | 85 |
| 1006 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:21:59 | 84 |
| 1006 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 81 |
| 1002 | 9001 | 2020-09-01 13:01:01 | 2020-09-01 13:41:01 | 81 |
| 1005 | 9001 | 2021-09-01 14:01:01 | (NULL) | (NULL) |
题目练习记录表 practice_record(uid 用户 ID, question_id 题目 ID, submit_time 提交时间, score 得分):
| uid | question_id | submit_time | score |
|---|---|---|---|
| 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
| 1004 | 8001 | 2021-08-02 19:38:01 | 70 |
| 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
| 1001 | 8002 | 2021-08-02 19:38:01 | 70 |
| 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
| 1006 | 8002 | 2021-08-04 19:58:01 | 94 |
| 1006 | 8003 | 2021-08-03 19:38:01 | 70 |
| 1006 | 8003 | 2021-08-02 19:48:01 | 90 |
| 1006 | 8003 | 2020-08-01 19:38:01 | 80 |
请统计每个 6/7 级用户总活跃月份数、2021 年活跃天数、2021 年试卷作答活跃天数、2021 年答题活跃天数,按照总活跃月份数、2021 年活跃天数降序排序。由示例数据结果输出如下:
| uid | act_month_total | act_days_2021 | act_days_2021_exam |
|---|---|---|---|
| 1006 | 3 | 4 | 1 |
| 1001 | 2 | 2 | 1 |
| 1005 | 1 | 1 | 1 |
| 1002 | 1 | 0 | 0 |
| 1003 | 0 | 0 | 0 |
解释:6/7 级用户共有 5 个,其中 1006 在 202109、202108、202008 共 3 个月活跃过,2021 年活跃的日期有 20210907、20210804、20210803、20210802 共 4 天,2021 年在试卷作答区 20210907 活跃 1 天,在题目练习区活跃了 3 天。
思路:
这题的关键在于CASE WHEN THEN的使用,不然要写很多的left join 因为会产生很多的结果集。
CASE WHEN THEN语句是一种条件表达式,用于在 SQL 中根据条件执行不同的操作或返回不同的结果。
语法结构如下:
1 | CASE |
在这个结构中,可以根据需要添加多个WHEN子句,每个WHEN子句后面跟着一个条件(condition)和一个结果(result)。条件可以是任何逻辑表达式,如果满足条件,将返回对应的结果。
最后的ELSE子句是可选的,用于指定当所有前面的条件都不满足时的默认返回结果。如果没有提供ELSE子句,则默认返回NULL。
例如:
1 | SELECT score, |
在上述示例中,根据学生成绩(score)的不同范围,使用 CASE WHEN THEN 语句返回相应的等级(grade)。如果成绩大于等于 90,则返回”优秀”;如果成绩大于等于 80,则返回”良好”;如果成绩大于等于 60,则返回”及格”;否则返回”不及格”。
那了解到了上述的用法之后,回过头看看该题,要求列出不同的活跃天数。
1 | count(distinct act_month) as act_month_total, |
这里的 tag 是先给标记,方便对查询进行区分,将考试和答题分开。
找出试卷作答区的用户
1 | SELECT |
紧接着就是答题作答区的用户
1 | SELECT |
最后将两个结果进行UNION 最后别忘了将结果进行排序 (这题有点类似于分治法的思想)
答案:
1 | SELECT user_info.uid, |
Vue精要
Vue.js 基础知识与特性
1. 简单使用总结
1.1 使用 Vue 实例管理 DOM
- 核心思想:Vue 实例将页面元素和数据联系起来,通过双向绑定机制,使开发者只需关注数据和事件的处理,无需手动修改视图。
- DOM 与数据/事件绑定:Vue 提供了简洁的语法来实现数据绑定和事件监听,使得开发更加高效。
1.2 Vue 实例的工作过程
- HTML 加载:首先加载 HTML 文件,包括容器(如
<div>)。 - Vue 初始化:创建 Vue 实例时,Vue 会解析绑定的容器中的模板,生成处理后的新容器,并替换原有的容器。
- 模板解析:容器中的代码成为模板,Vue 通过
{{}}占位符进行插值,类似于 MyBatis 中的${}和#{}。 - 容器与实例关系:容器和 Vue 实例是一对一的关系。在真实开发中,通常只会有一个 Vue 实例,并且会配合组件一起使用。
1.3 模板语法
- 插值:用于插入数据到标签内容中,如
{{ message }}。 - 指令:用于绑定属性、事件等,所有指令都以
v-开头,例如v-bind、v-on。
2. 组件化编程
2.1 组件的本质
- 组件是 Vue 实例:组件本质上是一个 Vue 实例,因此它可以接收
data、methods、生命周期函数等选项。 - 无
el属性:组件不会直接与页面元素绑定,否则无法复用。因此,组件没有el属性。 template属性:组件需要一个 HTML 模板,因此增加了template属性,其值为 HTML 模板。
2.2 组件定义
- 全局组件:定义完毕后,任何 Vue 实例都可以直接在 HTML 中通过组件名称来使用组件。
- 局部组件:仅在特定的 Vue 实例或父组件中注册和使用。
2.3 数据与方法
data必须是函数:为了确保每个组件实例都有独立的数据副本,data必须是一个返回对象的函数,而不是直接的对象。- 原型链:组件的构造函数(如
VueComponent)具有prototype属性,实例对象(如vc)则通过__proto__隐式引用构造函数的原型对象。
2.4 示例
1 | <!-- 全局组件 --> |
3. 生命周期
3.1 生命周期钩子
每个 Vue 实例在被创建时都要经过一系列的初始化过程,Vue 为生命周期中的每个状态都设置了钩子函数(监听函数)。每当 Vue 实例处于不同的生命周期阶段时,对应的函数就会被触发调用。
3.2 常见钩子函数
| 钩子函数 | 描述 |
|---|---|
beforeCreate |
在实例初始化之后,数据观测 (data observer) 和 event/watcher 事件配置之前被调用。 |
created |
在实例创建完成后被调用,此时已完成数据观测、属性和方法的运算,但尚未挂载到 DOM。 |
beforeMount |
在挂载开始之前被调用,相关的 render 函数首次被调用。 |
mounted |
在实例挂载到 DOM 后被调用,此时可以访问到真实的 DOM 节点。 |
beforeUpdate |
在数据更新时调用,发生在虚拟 DOM 打补丁之前。 |
updated |
在数据更新后,虚拟 DOM 重新渲染并打补丁后调用。 |
beforeDestroy |
在实例销毁之前调用,此时实例仍然完全可用。 |
destroyed |
在实例销毁后调用,此时所有的事件监听器和子组件都被移除。 |
3.3 生命周期图示
1 | beforeCreate → created → beforeMount → mounted → beforeUpdate → updated → beforeDestroy → destroyed |
4. 运行流程
4.1 页面加载
- 进入页面:首先加载
index.html和main.js文件。 - 导入模块:
main.js导入了vue、app、router等模块,并创建 Vue 实例,关联index.html页面的元素。 - 使用路由:
main.js导入了App组件,并通过<router-view>标签引用该组件。 - 默认显示:第一次访问时,默认显示
App组件。App组件包含一个图片和一个代表路由视图的<router-view>。由于路由路径默认使用 HASH 模式(/#/),因此会显示HelloWorld组件。
4.2 组件跳转
- 自定义组件:可以尝试自己编写一个组件,并将其加入路由配置中。
- 点击跳转:通过点击按钮或其他方式,可以触发路由跳转,显示不同的组件。
4.3 示例
1 | <!-- index.html --> |
1 | // main.js |
1 | // router/index.js |
1 | <!-- App.vue --> |
1 | <!-- HelloWorld.vue --> |
1 | <!-- MyComponent.vue --> |
和为k的问题
通用思想:
按照和是否等于k的情况,可以分为***++查找问题、搜索问题++***(本质上是一样的),因此可以用++特殊数据结构来存储和查找(哈希表、前缀数组)、暴力搜索、递归、分治,回溯法其实就是暴力法,进一步地记忆化搜索、动态规划来处理++。
先考虑该问题是否可以用特殊的数据结构来解决,再考虑算法。
更进一步地,按照题目给定数组的条件,使用滑动窗口、双指针、二分法都可以来解决,通常辅以前缀数组、后缀数组会大大简化。
通过前缀数组,区间和可以转换为两个前缀数组的差。
0-1背包问题就是动态规划的运用。
注意数组中是否有负数的情况又不一样,数组中均为正数的情况,会更简单些,往往可以直接用二分或者滑动窗口。
有负数时,可以考虑用单调栈、队列等辅助的数据结构,来进行滑动窗口。(leetcode862)
和为k的子数组:
相对于原问题更简单,附加了连续性,即缩小了范围,增加了遍历条件线索。
方法:
双层循环O(N2)
前缀和+map。这个表对应的映射项可以是最早出现这个sum的index(以此来求最长子数组的长度),也可以是对应这个sum出现的次数(对应求满足条件的子数组个数)。
变式:
在原问题基础上,增加了数组中的值均为正数的约束,因此数组和天然存在了递增的特性,可以采用滑动窗口的思想。
子数组和小于等于定值
子数组中均为正整数:
子数组中有负数:
这个题目应该是求和小于等于K的最长子数组。按理说,存在负数的话,是不能使用滑动窗口的,但是下面的解法借助两个辅助数组
使用两个辅助数组:min_value、min_index:min_value[i]表示以i位置开始往后加的最小累加和;min_index表示min_value对应的最小累加和的右边界;这两个辅助数组是能够在O(n)时间复杂内计算出来的:倒序遍历,min_value[i] 只需要判断min_value[i+1]的值是不是负数,如果是负数就加上,不是就到本身这里结尾。得到这样一个数组以后我们就可能轻易得到从某一个位置开始和最小的子数组。
有了这两个辅助数组以后,就可以采用滑动窗口的思想,左右两个指针都不回退,右指针以上面辅助数组进行累加,左指针正常遍历,使得总体的时间复杂度为O(n),参考LeetCode总结——和为定值 | Sixzeroo (liuin.cn)
SQL常见面试题总结(1)
题目来源于:牛客题霸 - SQL 必知必会
检索数据
SELECT 用于从数据库中查询数据。
从 Customers 表中检索所有的 ID
现有表 Customers 如下:
| cust_id |
|---|
| A |
| B |
| C |
编写 SQL 语句,从 Customers 表中检索所有的 cust_id。
答案:
1 | SELECT cust_id |
检索并列出已订购产品的清单
表 OrderItems 含有非空的列 prod_id 代表商品 id,包含了所有已订购的商品(有些已被订购多次)。
| prod_id |
|---|
| a1 |
| a2 |
| a3 |
| a4 |
| a5 |
| a6 |
| a7 |
编写 SQL 语句,检索并列出所有已订购商品(prod_id)的去重后的清单。
答案:
1 | SELECT DISTINCT prod_id |
知识点:DISTINCT 用于返回列中的唯一不同值。
检索所有列
现在有 Customers 表(表中含有列 cust_id 代表客户 id,cust_name 代表客户姓名)
| cust_id | cust_name |
|---|---|
| a1 | andy |
| a2 | ben |
| a3 | tony |
| a4 | tom |
| a5 | an |
| a6 | lee |
| a7 | hex |
需要编写 SQL 语句,检索所有列。
答案:
1 | SELECT cust_id, cust_name |
排序检索数据
ORDER BY 用于对结果集按照一个列或者多个列进行排序。默认按照升序对记录进行排序,如果需要按照降序对记录进行排序,可以使用 DESC 关键字。
检索顾客名称并且排序
有表 Customers,cust_id 代表客户 id,cust_name 代表客户姓名。
| cust_id | cust_name |
|---|---|
| a1 | andy |
| a2 | ben |
| a3 | tony |
| a4 | tom |
| a5 | an |
| a6 | lee |
| a7 | hex |
从 Customers 中检索所有的顾客名称(cust_name),并按从 Z 到 A 的顺序显示结果。
答案:
1 | SELECT cust_name |
对顾客 ID 和日期排序
有 Orders 表:
| cust_id | order_num | order_date |
|---|---|---|
| andy | aaaa | 2021-01-01 00:00:00 |
| andy | bbbb | 2021-01-01 12:00:00 |
| bob | cccc | 2021-01-10 12:00:00 |
| dick | dddd | 2021-01-11 00:00:00 |
编写 SQL 语句,从 Orders 表中检索顾客 ID(cust_id)和订单号(order_num),并先按顾客 ID 对结果进行排序,再按订单日期倒序排列。
答案:
1 | # 根据列名排序 |
知识点:order by 对多列排序的时候,先排序的列放前面,后排序的列放后面。并且,不同的列可以有不同的排序规则。
按照数量和价格排序
假设有一个 OrderItems 表:
| quantity | item_price |
|---|---|
| 1 | 100 |
| 10 | 1003 |
| 2 | 500 |
编写 SQL 语句,显示 OrderItems 表中的数量(quantity)和价格(item_price),并按数量由多到少、价格由高到低排序。
答案:
1 | SELECT quantity, item_price |
检查 SQL 语句
有 Vendors 表:
| vend_name |
|---|
| 海底捞 |
| 小龙坎 |
| 大龙燚 |
下面的 SQL 语句有问题吗?尝试将它改正确,使之能够正确运行,并且返回结果根据vend_name 逆序排列。
1 | SELECT vend_name, |
改正后:
1 | SELECT vend_name |
知识点:
- 逗号作用是用来隔开列与列之间的。
- ORDER BY 是有 BY 的,需要撰写完整,且位置正确。
过滤数据
WHERE 可以过滤返回的数据。
下面的运算符可以在 WHERE 子句中使用:
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于。 注释: 在 SQL 的一些版本中,该操作符可被写成 != |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN | 在某个范围内 |
| LIKE | 搜索某种模式 |
| IN | 指定针对某个列的多个可能值 |
返回固定价格的产品
有表 Products:
| prod_id | prod_name | prod_price |
|---|---|---|
| a0018 | sockets | 9.49 |
| a0019 | iphone13 | 600 |
| b0018 | gucci t-shirts | 1000 |
【问题】从 Products 表中检索产品 ID(prod_id)和产品名称(prod_name),只返回价格为 9.49 美元的产品。
答案:
1 | SELECT prod_id, prod_name |
返回更高价格的产品
有表 Products:
| prod_id | prod_name | prod_price |
|---|---|---|
| a0018 | sockets | 9.49 |
| a0019 | iphone13 | 600 |
| b0019 | gucci t-shirts | 1000 |
【问题】编写 SQL 语句,从 Products 表中检索产品 ID(prod_id)和产品名称(prod_name),只返回价格为 9 美元或更高的产品。
答案:
1 | SELECT prod_id, prod_name |
返回产品并且按照价格排序
有表 Products:
| prod_id | prod_name | prod_price |
|---|---|---|
| a0011 | egg | 3 |
| a0019 | sockets | 4 |
| b0019 | coffee | 15 |
【问题】编写 SQL 语句,返回 Products 表中所有价格在 3 美元到 6 美元之间的产品的名称(prod_name)和价格(prod_price),然后按价格对结果进行排序。
答案:
1 | SELECT prod_name, prod_price |
返回更多的产品
OrderItems 表含有:订单号 order_num,quantity产品数量
| order_num | quantity |
|---|---|
| a1 | 105 |
| a2 | 1100 |
| a2 | 200 |
| a4 | 1121 |
| a5 | 10 |
| a2 | 19 |
| a7 | 5 |
【问题】从 OrderItems 表中检索出所有不同且不重复的订单号(order_num),其中每个订单都要包含 100 个或更多的产品。
答案:
1 | SELECT order_num |
高级数据过滤
AND 和 OR 运算符用于基于一个以上的条件对记录进行过滤,两者可以结合使用。AND 必须 2 个条件都成立,OR只要 2 个条件中的一个成立即可。
检索供应商名称
Vendors 表有字段供应商名称(vend_name)、供应商国家(vend_country)、供应商州(vend_state)
| vend_name | vend_country | vend_state |
|---|---|---|
| apple | USA | CA |
| vivo | CNA | shenzhen |
| huawei | CNA | xian |
【问题】编写 SQL 语句,从 Vendors 表中检索供应商名称(vend_name),仅返回加利福尼亚州的供应商(这需要按国家[USA]和州[CA]进行过滤,没准其他国家也存在一个 CA)
答案:
1 | SELECT vend_name |
检索并列出已订购产品的清单
OrderItems 表包含了所有已订购的产品(有些已被订购多次)。
| prod_id | order_num | quantity |
|---|---|---|
| BR01 | a1 | 105 |
| BR02 | a2 | 1100 |
| BR02 | a2 | 200 |
| BR03 | a4 | 1121 |
| BR017 | a5 | 10 |
| BR02 | a2 | 19 |
| BR017 | a7 | 5 |
【问题】编写 SQL 语句,查找所有订购了数量至少 100 个的 BR01、BR02 或 BR03 的订单。你需要返回 OrderItems 表的订单号(order_num)、产品 ID(prod_id)和数量(quantity),并按产品 ID 和数量进行过滤。
答案:
1 | SELECT order_num, prod_id, quantity |
返回所有价格在 3 美元到 6 美元之间的产品的名称和价格
有表 Products:
| prod_id | prod_name | prod_price |
|---|---|---|
| a0011 | egg | 3 |
| a0019 | sockets | 4 |
| b0019 | coffee | 15 |
【问题】编写 SQL 语句,返回所有价格在 3 美元到 6 美元之间的产品的名称(prod_name)和价格(prod_price),使用 AND 操作符,然后按价格对结果进行升序排序。
答案:
1 | SELECT prod_name, prod_price |
检查 SQL 语句
供应商表 Vendors 有字段供应商名称 vend_name、供应商国家 vend_country、供应商省份 vend_state
| vend_name | vend_country | vend_state |
|---|---|---|
| apple | USA | CA |
| vivo | CNA | shenzhen |
| huawei | CNA | xian |
【问题】修改正确下面 sql,使之正确返回。
1 | SELECT vend_name |
修改后:
1 | SELECT vend_name |
ORDER BY 语句必须放在 WHERE 之后。
用通配符进行过滤
SQL 通配符必须与 LIKE 运算符一起使用
在 SQL 中,可使用以下通配符:
| 通配符 | 描述 |
|---|---|
% |
代表零个或多个字符 |
_ |
仅替代一个字符 |
[charlist] |
字符列中的任何单一字符 |
[^charlist] 或者 [!charlist] |
不在字符列中的任何单一字符 |
检索产品名称和描述(一)
Products 表如下:
| prod_name | prod_desc |
|---|---|
| a0011 | usb |
| a0019 | iphone13 |
| b0019 | gucci t-shirts |
| c0019 | gucci toy |
| d0019 | lego toy |
【问题】编写 SQL 语句,从 Products 表中检索产品名称(prod_name)和描述(prod_desc),仅返回描述中包含 toy 一词的产品名称。
答案:
1 | SELECT prod_name, prod_desc |
检索产品名称和描述(二)
Products 表如下:
| prod_name | prod_desc |
|---|---|
| a0011 | usb |
| a0019 | iphone13 |
| b0019 | gucci t-shirts |
| c0019 | gucci toy |
| d0019 | lego toy |
【问题】编写 SQL 语句,从 Products 表中检索产品名称(prod_name)和描述(prod_desc),仅返回描述中未出现 toy 一词的产品,最后按”产品名称“对结果进行排序。
答案:
1 | SELECT prod_name, prod_desc |
检索产品名称和描述(三)
Products 表如下:
| prod_name | prod_desc |
|---|---|
| a0011 | usb |
| a0019 | iphone13 |
| b0019 | gucci t-shirts |
| c0019 | gucci toy |
| d0019 | lego carrots toy |
【问题】编写 SQL 语句,从 Products 表中检索产品名称(prod_name)和描述(prod_desc),仅返回描述中同时出现 toy 和 carrots 的产品。有好几种方法可以执行此操作,但对于这个挑战题,请使用 AND 和两个 LIKE 比较。
答案:
1 | SELECT prod_name, prod_desc |
检索产品名称和描述(四)
Products 表如下:
| prod_name | prod_desc |
|---|---|
| a0011 | usb |
| a0019 | iphone13 |
| b0019 | gucci t-shirts |
| c0019 | gucci toy |
| d0019 | lego toy carrots |
【问题】编写 SQL 语句,从 Products 表中检索产品名称(prod_name)和描述(prod_desc),仅返回在描述中以先后顺序同时出现 toy 和 carrots 的产品。提示:只需要用带有三个 % 符号的 LIKE 即可。
答案:
1 | SELECT prod_name, prod_desc |
创建计算字段
别名
别名的常见用法是在检索出的结果中重命名表的列字段(为了符合特定的报表要求或客户需求)。有表 Vendors 代表供应商信息,vend_id 供应商 id、vend_name 供应商名称、vend_address 供应商地址、vend_city 供应商城市。
| vend_id | vend_name | vend_address | vend_city |
|---|---|---|---|
| a001 | tencent cloud | address1 | shenzhen |
| a002 | huawei cloud | address2 | dongguan |
| a003 | aliyun cloud | address3 | hangzhou |
| a003 | netease cloud | address4 | guangzhou |
【问题】编写 SQL 语句,从 Vendors 表中检索 vend_id、vend_name、vend_address 和 vend_city,将 vend_name 重命名为 vname,将 vend_city 重命名为 vcity,将 vend_address 重命名为 vaddress,按供应商名称对结果进行升序排序。
答案:
1 | SELECT vend_id, vend_name AS vname, vend_address AS vaddress, vend_city AS vcity |
打折
我们的示例商店正在进行打折促销,所有产品均降价 10%。Products 表包含 prod_id 产品 id、prod_price 产品价格。
【问题】编写 SQL 语句,从 Products 表中返回 prod_id、prod_price 和 sale_price。sale_price 是一个包含促销价格的计算字段。提示:可以乘以 0.9,得到原价的 90%(即 10%的折扣)。
答案:
1 | SELECT prod_id, prod_price, prod_price * 0.9 AS sale_price |
注意:sale_price 是对计算结果的命名,而不是原有的列名。
使用函数处理数据
顾客登录名
我们的商店已经上线了,正在创建顾客账户。所有用户都需要登录名,默认登录名是其名称和所在城市的组合。
给出 Customers 表 如下:
| cust_id | cust_name | cust_contact | cust_city |
|---|---|---|---|
| a1 | Andy Li | Andy Li | Oak Park |
| a2 | Ben Liu | Ben Liu | Oak Park |
| a3 | Tony Dai | Tony Dai | Oak Park |
| a4 | Tom Chen | Tom Chen | Oak Park |
| a5 | An Li | An Li | Oak Park |
| a6 | Lee Chen | Lee Chen | Oak Park |
| a7 | Hex Liu | Hex Liu | Oak Park |
【问题】编写 SQL 语句,返回顾客 ID(cust_id)、顾客名称(cust_name)和登录名(user_login),其中登录名全部为大写字母,并由顾客联系人的前两个字符(cust_contact)和其所在城市的前三个字符(cust_city)组成。提示:需要使用函数、拼接和别名。
答案:
1 | SELECT cust_id, cust_name, UPPER(CONCAT(SUBSTRING(cust_contact, 1, 2), SUBSTRING(cust_city, 1, 3))) AS user_login |
知识点:
截取函数
SUBSTRING():截取字符串,substring(str ,n ,m)(n 表示起始截取位置,m 表示要截取的字符个数)表示返回字符串 str 从第 n 个字符开始截取 m 个字符;拼接函数
CONCAT():将两个或多个字符串连接成一个字符串,select concat(A,B):连接字符串 A 和 B。大写函数
UPPER():将指定字符串转换为大写。
返回 2020 年 1 月的所有订单的订单号和订单日期
Orders 订单表如下:
| order_num | order_date |
|---|---|
| a0001 | 2020-01-01 00:00:00 |
| a0002 | 2020-01-02 00:00:00 |
| a0003 | 2020-01-01 12:00:00 |
| a0004 | 2020-02-01 00:00:00 |
| a0005 | 2020-03-01 00:00:00 |
【问题】编写 SQL 语句,返回 2020 年 1 月的所有订单的订单号(order_num)和订单日期(order_date),并按订单日期升序排序
答案:
1 | SELECT order_num, order_date |
也可以用通配符来做:
1 | SELECT order_num, order_date |
知识点:
- 日期格式:
YYYY-MM-DD - 时间格式:
HH:MM:SS
日期和时间处理相关的常用函数:
| 函 数 | 说 明 |
|---|---|
ADDDATE() |
增加一个日期(天、周等) |
ADDTIME() |
增加一个时间(时、分等) |
CURDATE() |
返回当前日期 |
CURTIME() |
返回当前时间 |
DATE() |
返回日期时间的日期部分 |
DATEDIFF |
计算两个日期之差 |
DATE_FORMAT() |
返回一个格式化的日期或时间串 |
DAY() |
返回一个日期的天数部分 |
DAYOFWEEK() |
对于一个日期,返回对应的星期几 |
HOUR() |
返回一个时间的小时部分 |
MINUTE() |
返回一个时间的分钟部分 |
MONTH() |
返回一个日期的月份部分 |
NOW() |
返回当前日期和时间 |
SECOND() |
返回一个时间的秒部分 |
TIME() |
返回一个日期时间的时间部分 |
YEAR() |
返回一个日期的年份部分 |
汇总数据
汇总数据相关的函数:
| 函 数 | 说 明 |
|---|---|
AVG() |
返回某列的平均值 |
COUNT() |
返回某列的行数 |
MAX() |
返回某列的最大值 |
MIN() |
返回某列的最小值 |
SUM() |
返回某列值之和 |
确定已售出产品的总数
OrderItems 表代表售出的产品,quantity 代表售出商品数量。
| quantity |
|---|
| 10 |
| 100 |
| 1000 |
| 10001 |
| 2 |
| 15 |
【问题】编写 SQL 语句,确定已售出产品的总数。
答案:
1 | SELECT Sum(quantity) AS items_ordered |
确定已售出产品项 BR01 的总数
OrderItems 表代表售出的产品,quantity 代表售出商品数量,产品项为 prod_id。
| quantity | prod_id |
|---|---|
| 10 | AR01 |
| 100 | AR10 |
| 1000 | BR01 |
| 10001 | BR010 |
【问题】修改创建的语句,确定已售出产品项(prod_id)为”BR01”的总数。
答案:
1 | SELECT Sum(quantity) AS items_ordered |
确定 Products 表中价格不超过 10 美元的最贵产品的价格
Products 表如下,prod_price 代表商品的价格。
| prod_price |
|---|
| 9.49 |
| 600 |
| 1000 |
【问题】编写 SQL 语句,确定 Products 表中价格不超过 10 美元的最贵产品的价格(prod_price)。将计算所得的字段命名为 max_price。
答案:
1 | SELECT Max(prod_price) AS max_price |
分组数据
GROUP BY:
GROUP BY子句将记录分组到汇总行中。GROUP BY为每个组返回一个记录。GROUP BY通常还涉及聚合COUNT,MAX,SUM,AVG等。GROUP BY可以按一列或多列进行分组。GROUP BY按分组字段进行排序后,ORDER BY可以以汇总字段来进行排序。
HAVING:
HAVING用于对汇总的GROUP BY结果进行过滤。HAVING必须要与GROUP BY连用。WHERE和HAVING可以在相同的查询中。
HAVING vs WHERE:
WHERE:过滤指定的行,后面不能加聚合函数(分组函数)。HAVING:过滤分组,必须要与GROUP BY连用,不能单独使用。
返回每个订单号各有多少行数
OrderItems 表包含每个订单的每个产品
| order_num |
|---|
| a002 |
| a002 |
| a002 |
| a004 |
| a007 |
【问题】编写 SQL 语句,返回每个订单号(order_num)各有多少行数(order_lines),并按 order_lines 对结果进行升序排序。
答案:
1 | SELECT order_num, Count(order_num) AS order_lines |
知识点:
count(*),count(列名)都可以,区别在于,count(列名)是统计非 NULL 的行数;order by最后执行,所以可以使用列别名;- 分组聚合一定不要忘记加上
group by,不然只会有一行结果。
每个供应商成本最低的产品
有 Products 表,含有字段 prod_price 代表产品价格,vend_id 代表供应商 id
| vend_id | prod_price |
|---|---|
| a0011 | 100 |
| a0019 | 0.1 |
| b0019 | 1000 |
| b0019 | 6980 |
| b0019 | 20 |
【问题】编写 SQL 语句,返回名为 cheapest_item 的字段,该字段包含每个供应商成本最低的产品(使用 Products 表中的 prod_price),然后从最低成本到最高成本对结果进行升序排序。
答案:
1 | SELECT vend_id, Min(prod_price) AS cheapest_item |
返回订单数量总和不小于 100 的所有订单的订单号
OrderItems 代表订单商品表,包括:订单号 order_num 和订单数量 quantity。
| order_num | quantity |
|---|---|
| a1 | 105 |
| a2 | 1100 |
| a2 | 200 |
| a4 | 1121 |
| a5 | 10 |
| a2 | 19 |
| a7 | 5 |
【问题】请编写 SQL 语句,返回订单数量总和不小于 100 的所有订单号,最后结果按照订单号升序排序。
答案:
1 | # 直接聚合 |
知识点:
where:过滤过滤指定的行,后面不能加聚合函数(分组函数)。having:过滤分组,与group by连用,不能单独使用。
计算总和
OrderItems 表代表订单信息,包括字段:订单号 order_num 和 item_price 商品售出价格、quantity 商品数量。
| order_num | item_price | quantity |
|---|---|---|
| a1 | 10 | 105 |
| a2 | 1 | 1100 |
| a2 | 1 | 200 |
| a4 | 2 | 1121 |
| a5 | 5 | 10 |
| a2 | 1 | 19 |
| a7 | 7 | 5 |
【问题】编写 SQL 语句,根据订单号聚合,返回订单总价不小于 1000 的所有订单号,最后的结果按订单号进行升序排序。
提示:总价 = item_price 乘以 quantity
答案:
1 | SELECT order_num, Sum(item_price * quantity) AS total_price |
检查 SQL 语句
OrderItems 表含有 order_num 订单号
| order_num |
|---|
| a002 |
| a002 |
| a002 |
| a004 |
| a007 |
【问题】将下面代码修改正确后执行
1 | SELECT order_num, COUNT(*) AS items |
修改后:
1 | SELECT order_num, COUNT(*) AS items |
使用子查询
子查询是嵌套在较大查询中的 SQL 查询,也称内部查询或内部选择,包含子查询的语句也称为外部查询或外部选择。简单来说,子查询就是指将一个 SELECT 查询(子查询)的结果作为另一个 SQL 语句(主查询)的数据来源或者判断条件。
子查询可以嵌入 SELECT、INSERT、UPDATE 和 DELETE 语句中,也可以和 =、<、>、IN、BETWEEN、EXISTS 等运算符一起使用。
子查询常用在 WHERE 子句和 FROM 子句后边:
- 当用于
WHERE子句时,根据不同的运算符,子查询可以返回单行单列、多行单列、单行多列数据。子查询就是要返回能够作为 WHERE 子句查询条件的值。 - 当用于
FROM子句时,一般返回多行多列数据,相当于返回一张临时表,这样才符合FROM后面是表的规则。这种做法能够实现多表联合查询。
注意:MySQL 数据库从 4.1 版本才开始支持子查询,早期版本是不支持的。
用于 WHERE 子句的子查询的基本语法如下:
1 | SELECT column_name [, column_name ] |
- 子查询需要放在括号
( )内。 operator表示用于WHERE子句的运算符,可以是比较运算符(如=,<,>,<>等)或逻辑运算符(如IN,NOT IN,EXISTS,NOT EXISTS等),具体根据需求来确定。
用于 FROM 子句的子查询的基本语法如下:
1 | SELECT column_name [, column_name ] |
- 用于
FROM的子查询返回的结果相当于一张临时表,所以需要使用 AS 关键字为该临时表起一个名字。 - 子查询需要放在括号
( )内。 - 可以指定多个临时表名,并使用
JOIN语句连接这些表。
返回购买价格为 10 美元或以上产品的顾客列表
OrderItems 表示订单商品表,含有字段订单号:order_num、订单价格:item_price;Orders 表代表订单信息表,含有顾客 id:cust_id 和订单号:order_num
OrderItems 表:
| order_num | item_price |
|---|---|
| a1 | 10 |
| a2 | 1 |
| a2 | 1 |
| a4 | 2 |
| a5 | 5 |
| a2 | 1 |
| a7 | 7 |
Orders 表:
| order_num | cust_id |
|---|---|
| a1 | cust10 |
| a2 | cust1 |
| a2 | cust1 |
| a4 | cust2 |
| a5 | cust5 |
| a2 | cust1 |
| a7 | cust7 |
【问题】使用子查询,返回购买价格为 10 美元或以上产品的顾客列表,结果无需排序。
答案:
1 | SELECT cust_id |
确定哪些订单购买了 prod_id 为 BR01 的产品(一)
表 OrderItems 代表订单商品信息表,prod_id 为产品 id;Orders 表代表订单表有 cust_id 代表顾客 id 和订单日期 order_date
OrderItems 表:
| prod_id | order_num |
|---|---|
| BR01 | a0001 |
| BR01 | a0002 |
| BR02 | a0003 |
| BR02 | a0013 |
Orders 表:
| order_num | cust_id | order_date |
|---|---|---|
| a0001 | cust10 | 2022-01-01 00:00:00 |
| a0002 | cust1 | 2022-01-01 00:01:00 |
| a0003 | cust1 | 2022-01-02 00:00:00 |
| a0013 | cust2 | 2022-01-01 00:20:00 |
【问题】
编写 SQL 语句,使用子查询来确定哪些订单(在 OrderItems 中)购买了 prod_id 为 “BR01” 的产品,然后从 Orders 表中返回每个产品对应的顾客 ID(cust_id)和订单日期(order_date),按订购日期对结果进行升序排序。
答案:
1 | # 写法 1:子查询 |
返回购买 prod_id 为 BR01 的产品的所有顾客的电子邮件(一)
你想知道订购 BR01 产品的日期,有表 OrderItems 代表订单商品信息表,prod_id 为产品 id;Orders 表代表订单表有 cust_id 代表顾客 id 和订单日期 order_date;Customers 表含有 cust_email 顾客邮件和 cust_id 顾客 id
OrderItems 表:
| prod_id | order_num |
|---|---|
| BR01 | a0001 |
| BR01 | a0002 |
| BR02 | a0003 |
| BR02 | a0013 |
Orders 表:
| order_num | cust_id | order_date |
|---|---|---|
| a0001 | cust10 | 2022-01-01 00:00:00 |
| a0002 | cust1 | 2022-01-01 00:01:00 |
| a0003 | cust1 | 2022-01-02 00:00:00 |
| a0013 | cust2 | 2022-01-01 00:20:00 |
Customers 表代表顾客信息,cust_id 为顾客 id,cust_email 为顾客 email
| cust_id | cust_email |
|---|---|
| cust10 | cust10@cust.com |
| cust1 | cust1@cust.com |
| cust2 | cust2@cust.com |
【问题】返回购买 prod_id 为 BR01 的产品的所有顾客的电子邮件(Customers 表中的 cust_email),结果无需排序。
提示:这涉及 SELECT 语句,最内层的从 OrderItems 表返回 order_num,中间的从 Customers 表返回 cust_id。
答案:
1 | # 写法 1:子查询 |
返回每个顾客不同订单的总金额
我们需要一个顾客 ID 列表,其中包含他们已订购的总金额。
OrderItems 表代表订单信息,OrderItems 表有订单号:order_num 和商品售出价格:item_price、商品数量:quantity。
| order_num | item_price | quantity |
|---|---|---|
| a0001 | 10 | 105 |
| a0002 | 1 | 1100 |
| a0002 | 1 | 200 |
| a0013 | 2 | 1121 |
| a0003 | 5 | 10 |
| a0003 | 1 | 19 |
| a0003 | 7 | 5 |
Orders 表订单号:order_num、顾客 id:cust_id
| order_num | cust_id |
|---|---|
| a0001 | cust10 |
| a0002 | cust1 |
| a0003 | cust1 |
| a0013 | cust2 |
【问题】
编写 SQL 语句,返回顾客 ID(Orders 表中的 cust_id),并使用子查询返回 total_ordered 以便返回每个顾客的订单总数,将结果按金额从大到小排序。
答案:
1 | # 写法 1:子查询 |
关于写法一详细介绍可以参考: issue#2402:写法 1 存在的错误以及修改方法。
从 Products 表中检索所有的产品名称以及对应的销售总数
Products 表中检索所有的产品名称:prod_name、产品 id:prod_id
| prod_id | prod_name |
|---|---|
| a0001 | egg |
| a0002 | sockets |
| a0013 | coffee |
| a0003 | cola |
OrderItems 代表订单商品表,订单产品:prod_id、售出数量:quantity
| prod_id | quantity |
|---|---|
| a0001 | 105 |
| a0002 | 1100 |
| a0002 | 200 |
| a0013 | 1121 |
| a0003 | 10 |
| a0003 | 19 |
| a0003 | 5 |
【问题】
编写 SQL 语句,从 Products 表中检索所有的产品名称(prod_name),以及名为 quant_sold 的计算列,其中包含所售产品的总数(在 OrderItems 表上使用子查询和 SUM(quantity) 检索)。
答案:
1 | # 写法 1:子查询 |
连接表
JOIN 是“连接”的意思,顾名思义,SQL JOIN 子句用于将两个或者多个表联合起来进行查询。
连接表时需要在每个表中选择一个字段,并对这些字段的值进行比较,值相同的两条记录将合并为一条。连接表的本质就是将不同表的记录合并起来,形成一张新表。当然,这张新表只是临时的,它仅存在于本次查询期间。
使用 JOIN 连接两个表的基本语法如下:
1 | SELECT table1.column1, table2.column2... |
table1.common_column1 = table2.common_column2 是连接条件,只有满足此条件的记录才会合并为一行。您可以使用多个运算符来连接表,例如 =、>、<、<>、<=、>=、!=、between、like 或者 not,但是最常见的是使用 =。
当两个表中有同名的字段时,为了帮助数据库引擎区分是哪个表的字段,在书写同名字段名时需要加上表名。当然,如果书写的字段名在两个表中是唯一的,也可以不使用以上格式,只写字段名即可。
另外,如果两张表的关联字段名相同,也可以使用 USING子句来代替 ON,举个例子:
1 | # join....on |
ON 和 WHERE 的区别:
- 连接表时,SQL 会根据连接条件生成一张新的临时表。
ON就是连接条件,它决定临时表的生成。 WHERE是在临时表生成以后,再对临时表中的数据进行过滤,生成最终的结果集,这个时候已经没有 JOIN-ON 了。
所以总结来说就是:SQL 先根据 ON 生成一张临时表,然后再根据 WHERE 对临时表进行筛选。
SQL 允许在 JOIN 左边加上一些修饰性的关键词,从而形成不同类型的连接,如下表所示:
| 连接类型 | 说明 |
|---|---|
| INNER JOIN 内连接 | (默认连接方式)只有当两个表都存在满足条件的记录时才会返回行。 |
| LEFT JOIN / LEFT OUTER JOIN 左(外)连接 | 返回左表中的所有行,即使右表中没有满足条件的行也是如此。 |
| RIGHT JOIN / RIGHT OUTER JOIN 右(外)连接 | 返回右表中的所有行,即使左表中没有满足条件的行也是如此。 |
| FULL JOIN / FULL OUTER JOIN 全(外)连接 | 只要其中有一个表存在满足条件的记录,就返回行。 |
| SELF JOIN | 将一个表连接到自身,就像该表是两个表一样。为了区分两个表,在 SQL 语句中需要至少重命名一个表。 |
| CROSS JOIN | 交叉连接,从两个或者多个连接表中返回记录集的笛卡尔积。 |
下图展示了 LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN 相关的 7 种用法。
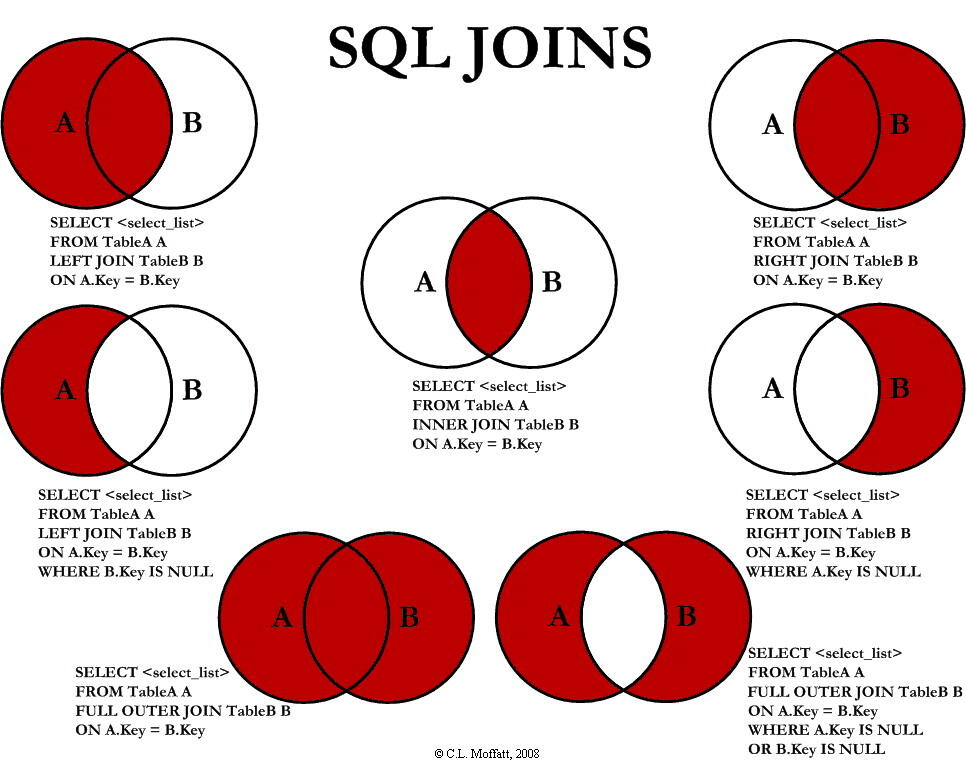
如果不加任何修饰词,只写 JOIN,那么默认为 INNER JOIN
对于 INNER JOIN 来说,还有一种隐式的写法,称为 “隐式内连接”,也就是没有 INNER JOIN 关键字,使用 WHERE 语句实现内连接的功能
1 | # 隐式内连接 |
返回顾客名称和相关订单号
Customers 表有字段顾客名称 cust_name、顾客 id cust_id
| cust_id | cust_name |
|---|---|
| cust10 | andy |
| cust1 | ben |
| cust2 | tony |
| cust22 | tom |
| cust221 | an |
| cust2217 | hex |
Orders 订单信息表,含有字段 order_num 订单号、cust_id 顾客 id
| order_num | cust_id |
|---|---|
| a1 | cust10 |
| a2 | cust1 |
| a3 | cust2 |
| a4 | cust22 |
| a5 | cust221 |
| a7 | cust2217 |
【问题】编写 SQL 语句,返回 Customers 表中的顾客名称(cust_name)和 Orders 表中的相关订单号(order_num),并按顾客名称再按订单号对结果进行升序排序。你可以尝试用两个不同的写法,一个使用简单的等连接语法,另外一个使用 INNER JOIN。
答案:
1 | # 隐式内连接 |
返回顾客名称和相关订单号以及每个订单的总价
Customers 表有字段,顾客名称:cust_name、顾客 id:cust_id
| cust_id | cust_name |
|---|---|
| cust10 | andy |
| cust1 | ben |
| cust2 | tony |
| cust22 | tom |
| cust221 | an |
| cust2217 | hex |
Orders 订单信息表,含有字段,订单号:order_num、顾客 id:cust_id
| order_num | cust_id |
|---|---|
| a1 | cust10 |
| a2 | cust1 |
| a3 | cust2 |
| a4 | cust22 |
| a5 | cust221 |
| a7 | cust2217 |
OrderItems 表有字段,商品订单号:order_num、商品数量:quantity、商品价格:item_price
| order_num | quantity | item_price |
|---|---|---|
| a1 | 1000 | 10 |
| a2 | 200 | 10 |
| a3 | 10 | 15 |
| a4 | 25 | 50 |
| a5 | 15 | 25 |
| a7 | 7 | 7 |
【问题】除了返回顾客名称和订单号,返回 Customers 表中的顾客名称(cust_name)和 Orders 表中的相关订单号(order_num),添加第三列 OrderTotal,其中包含每个订单的总价,并按顾客名称再按订单号对结果进行升序排序。
1 | # 简单的等连接语法 |
注意,可能有小伙伴会这样写:
1 | SELECT c.cust_name, o.order_num, SUM(quantity * item_price) AS OrderTotal |
这是错误的!只对 cust_name 进行聚类确实符合题意,但是不符合 GROUP BY 的语法。
select 语句中,如果没有 GROUP BY 语句,那么 cust_name、order_num 会返回若干个值,而 sum(quantity * item_price) 只返回一个值,通过 group by cust_name 可以让 cust_name 和 sum(quantity * item_price) 一一对应起来,或者说聚类,所以同样的,也要对 order_num 进行聚类。
一句话,select 中的字段要么都聚类,要么都不聚类
确定哪些订单购买了 prod_id 为 BR01 的产品(二)
表 OrderItems 代表订单商品信息表,prod_id 为产品 id;Orders 表代表订单表有 cust_id 代表顾客 id 和订单日期 order_date
OrderItems 表:
| prod_id | order_num |
|---|---|
| BR01 | a0001 |
| BR01 | a0002 |
| BR02 | a0003 |
| BR02 | a0013 |
Orders 表:
| order_num | cust_id | order_date |
|---|---|---|
| a0001 | cust10 | 2022-01-01 00:00:00 |
| a0002 | cust1 | 2022-01-01 00:01:00 |
| a0003 | cust1 | 2022-01-02 00:00:00 |
| a0013 | cust2 | 2022-01-01 00:20:00 |
【问题】
编写 SQL 语句,使用子查询来确定哪些订单(在 OrderItems 中)购买了 prod_id 为 “BR01” 的产品,然后从 Orders 表中返回每个产品对应的顾客 ID(cust_id)和订单日期(order_date),按订购日期对结果进行升序排序。
提示:这一次使用连接和简单的等连接语法。
1 | # 写法 1:子查询 |
返回购买 prod_id 为 BR01 的产品的所有顾客的电子邮件(二)
有表 OrderItems 代表订单商品信息表,prod_id 为产品 id;Orders 表代表订单表有 cust_id 代表顾客 id 和订单日期 order_date;Customers 表含有 cust_email 顾客邮件和 cust_id 顾客 id
OrderItems 表:
| prod_id | order_num |
|---|---|
| BR01 | a0001 |
| BR01 | a0002 |
| BR02 | a0003 |
| BR02 | a0013 |
Orders 表:
| order_num | cust_id | order_date |
|---|---|---|
| a0001 | cust10 | 2022-01-01 00:00:00 |
| a0002 | cust1 | 2022-01-01 00:01:00 |
| a0003 | cust1 | 2022-01-02 00:00:00 |
| a0013 | cust2 | 2022-01-01 00:20:00 |
Customers 表代表顾客信息,cust_id 为顾客 id,cust_email 为顾客 email
| cust_id | cust_email |
|---|---|
| cust10 | cust10@cust.com |
| cust1 | cust1@cust.com |
| cust2 | cust2@cust.com |
【问题】返回购买 prod_id 为 BR01 的产品的所有顾客的电子邮件(Customers 表中的 cust_email),结果无需排序。
提示:涉及到 SELECT 语句,最内层的从 OrderItems 表返回 order_num,中间的从 Customers 表返回 cust_id,但是必须使用 INNER JOIN 语法。
1 | SELECT cust_email |
确定最佳顾客的另一种方式(二)
OrderItems 表代表订单信息,确定最佳顾客的另一种方式是看他们花了多少钱,OrderItems 表有订单号 order_num 和 item_price 商品售出价格、quantity 商品数量
| order_num | item_price | quantity |
|---|---|---|
| a1 | 10 | 105 |
| a2 | 1 | 1100 |
| a2 | 1 | 200 |
| a4 | 2 | 1121 |
| a5 | 5 | 10 |
| a2 | 1 | 19 |
| a7 | 7 | 5 |
Orders 表含有字段 order_num 订单号、cust_id 顾客 id
| order_num | cust_id |
|---|---|
| a1 | cust10 |
| a2 | cust1 |
| a3 | cust2 |
| a4 | cust22 |
| a5 | cust221 |
| a7 | cust2217 |
顾客表 Customers 有字段 cust_id 客户 id、cust_name 客户姓名
| cust_id | cust_name |
|---|---|
| cust10 | andy |
| cust1 | ben |
| cust2 | tony |
| cust22 | tom |
| cust221 | an |
| cust2217 | hex |
【问题】编写 SQL 语句,返回订单总价不小于 1000 的客户名称和总额(OrderItems 表中的 order_num)。
提示:需要计算总和(item_price 乘以 quantity)。按总额对结果进行排序,请使用 INNER JOIN语法。
1 | SELECT cust_name, SUM(item_price * quantity) AS total_price |
创建高级连接
检索每个顾客的名称和所有的订单号(一)
Customers 表代表顾客信息含有顾客 id cust_id 和 顾客名称 cust_name
| cust_id | cust_name |
|---|---|
| cust10 | andy |
| cust1 | ben |
| cust2 | tony |
| cust22 | tom |
| cust221 | an |
| cust2217 | hex |
Orders 表代表订单信息含有订单号 order_num 和顾客 id cust_id
| order_num | cust_id |
|---|---|
| a1 | cust10 |
| a2 | cust1 |
| a3 | cust2 |
| a4 | cust22 |
| a5 | cust221 |
| a7 | cust2217 |
【问题】使用 INNER JOIN 编写 SQL 语句,检索每个顾客的名称(Customers 表中的 cust_name)和所有的订单号(Orders 表中的 order_num),最后根据顾客姓名 cust_name 升序返回。
1 | SELECT cust_name, order_num |
检索每个顾客的名称和所有的订单号(二)
Orders 表代表订单信息含有订单号 order_num 和顾客 id cust_id
| order_num | cust_id |
|---|---|
| a1 | cust10 |
| a2 | cust1 |
| a3 | cust2 |
| a4 | cust22 |
| a5 | cust221 |
| a7 | cust2217 |
Customers 表代表顾客信息含有顾客 id cust_id 和 顾客名称 cust_name
| cust_id | cust_name |
|---|---|
| cust10 | andy |
| cust1 | ben |
| cust2 | tony |
| cust22 | tom |
| cust221 | an |
| cust2217 | hex |
| cust40 | ace |
【问题】检索每个顾客的名称(Customers 表中的 cust_name)和所有的订单号(Orders 表中的 order_num),列出所有的顾客,即使他们没有下过订单。最后根据顾客姓名 cust_name 升序返回。
1 | SELECT cust_name, order_num |
返回产品名称和与之相关的订单号
Products 表为产品信息表含有字段 prod_id 产品 id、prod_name 产品名称
| prod_id | prod_name |
|---|---|
| a0001 | egg |
| a0002 | sockets |
| a0013 | coffee |
| a0003 | cola |
| a0023 | soda |
OrderItems 表为订单信息表含有字段 order_num 订单号和产品 id prod_id
| prod_id | order_num |
|---|---|
| a0001 | a105 |
| a0002 | a1100 |
| a0002 | a200 |
| a0013 | a1121 |
| a0003 | a10 |
| a0003 | a19 |
| a0003 | a5 |
【问题】使用外连接(left join、 right join、full join)联结 Products 表和 OrderItems 表,返回产品名称(prod_name)和与之相关的订单号(order_num)的列表,并按照产品名称升序排序。
1 | SELECT prod_name, order_num |
返回产品名称和每一项产品的总订单数
Products 表为产品信息表含有字段 prod_id 产品 id、prod_name 产品名称
| prod_id | prod_name |
|---|---|
| a0001 | egg |
| a0002 | sockets |
| a0013 | coffee |
| a0003 | cola |
| a0023 | soda |
OrderItems 表为订单信息表含有字段 order_num 订单号和产品 id prod_id
| prod_id | order_num |
|---|---|
| a0001 | a105 |
| a0002 | a1100 |
| a0002 | a200 |
| a0013 | a1121 |
| a0003 | a10 |
| a0003 | a19 |
| a0003 | a5 |
【问题】
使用 OUTER JOIN 联结 Products 表和 OrderItems 表,返回产品名称(prod_name)和每一项产品的总订单数(不是订单号),并按产品名称升序排序。
1 | SELECT prod_name, COUNT(order_num) AS orders |
列出供应商及其可供产品的数量
有 Vendors 表含有 vend_id (供应商 id)
| vend_id |
|---|
| a0002 |
| a0013 |
| a0003 |
| a0010 |
有 Products 表含有 vend_id(供应商 id)和 prod_id(供应产品 id)
| vend_id | prod_id |
|---|---|
| a0001 | egg |
| a0002 | prod_id_iphone |
| a00113 | prod_id_tea |
| a0003 | prod_id_vivo phone |
| a0010 | prod_id_huawei phone |
【问题】列出供应商(Vendors 表中的 vend_id)及其可供产品的数量,包括没有产品的供应商。你需要使用 OUTER JOIN 和 COUNT()聚合函数来计算 Products 表中每种产品的数量,最后根据 vend_id 升序排序。
注意:vend_id 列会显示在多个表中,因此在每次引用它时都需要完全限定它。
1 | SELECT v.vend_id, COUNT(prod_id) AS prod_id |
组合查询
UNION 运算符将两个或更多查询的结果组合起来,并生成一个结果集,其中包含来自 UNION 中参与查询的提取行。
UNION 基本规则:
- 所有查询的列数和列顺序必须相同。
- 每个查询中涉及表的列的数据类型必须相同或兼容。
- 通常返回的列名取自第一个查询。
默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
1 | SELECT column_name(s) FROM table1 |
UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
JOIN vs UNION:
JOIN中连接表的列可能不同,但在UNION中,所有查询的列数和列顺序必须相同。UNION将查询之后的行放在一起(垂直放置),但JOIN将查询之后的列放在一起(水平放置),即它构成一个笛卡尔积。
将两个 SELECT 语句结合起来(一)
表 OrderItems 包含订单产品信息,字段 prod_id 代表产品 id、quantity 代表产品数量
| prod_id | quantity |
|---|---|
| a0001 | 105 |
| a0002 | 100 |
| a0002 | 200 |
| a0013 | 1121 |
| a0003 | 10 |
| a0003 | 19 |
| a0003 | 5 |
| BNBG | 10002 |
【问题】将两个 SELECT 语句结合起来,以便从 OrderItems 表中检索产品 id(prod_id)和 quantity。其中,一个 SELECT 语句过滤数量为 100 的行,另一个 SELECT 语句过滤 id 以 BNBG 开头的产品,最后按产品 id 对结果进行升序排序。
1 | SELECT prod_id, quantity |
将两个 SELECT 语句结合起来(二)
表 OrderItems 包含订单产品信息,字段 prod_id 代表产品 id、quantity 代表产品数量。
| prod_id | quantity |
|---|---|
| a0001 | 105 |
| a0002 | 100 |
| a0002 | 200 |
| a0013 | 1121 |
| a0003 | 10 |
| a0003 | 19 |
| a0003 | 5 |
| BNBG | 10002 |
【问题】将两个 SELECT 语句结合起来,以便从 OrderItems 表中检索产品 id(prod_id)和 quantity。其中,一个 SELECT 语句过滤数量为 100 的行,另一个 SELECT 语句过滤 id 以 BNBG 开头的产品,最后按产品 id 对结果进行升序排序。 注意:这次仅使用单个 SELECT 语句。
答案:
要求只用一条 select 语句,那就用 or 不用 union 了。
1 | SELECT prod_id, quantity |
组合 Products 表中的产品名称和 Customers 表中的顾客名称
Products 表含有字段 prod_name 代表产品名称
| prod_name |
|---|
| flower |
| rice |
| ring |
| umbrella |
Customers 表代表顾客信息,cust_name 代表顾客名称
| cust_name |
|---|
| andy |
| ben |
| tony |
| tom |
| an |
| lee |
| hex |
【问题】编写 SQL 语句,组合 Products 表中的产品名称(prod_name)和 Customers 表中的顾客名称(cust_name)并返回,然后按产品名称对结果进行升序排序。
1 | # UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。 |
检查 SQL 语句
表 Customers 含有字段 cust_name 顾客名、cust_contact 顾客联系方式、cust_state 顾客州、cust_email 顾客 email
| cust_name | cust_contact | cust_state | cust_email |
|---|---|---|---|
| cust10 | 8695192 | MI | cust10@cust.com |
| cust1 | 8695193 | MI | cust1@cust.com |
| cust2 | 8695194 | IL | cust2@cust.com |
【问题】修正下面错误的 SQL
1 | SELECT cust_name, cust_contact, cust_email |
修正后:
1 | SELECT cust_name, cust_contact, cust_email |
使用 union 组合查询时,只能使用一条 order by 字句,他必须位于最后一条 select 语句之后
或者直接用 or 来做:
1 | SELECT cust_name, cust_contact, cust_email |